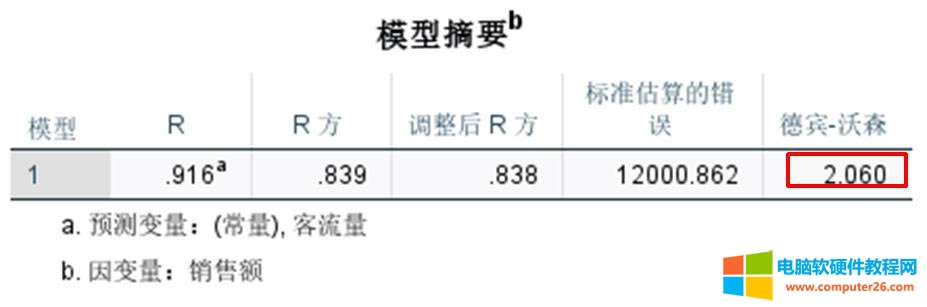
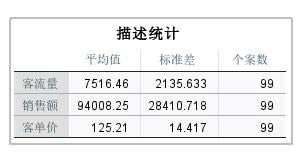
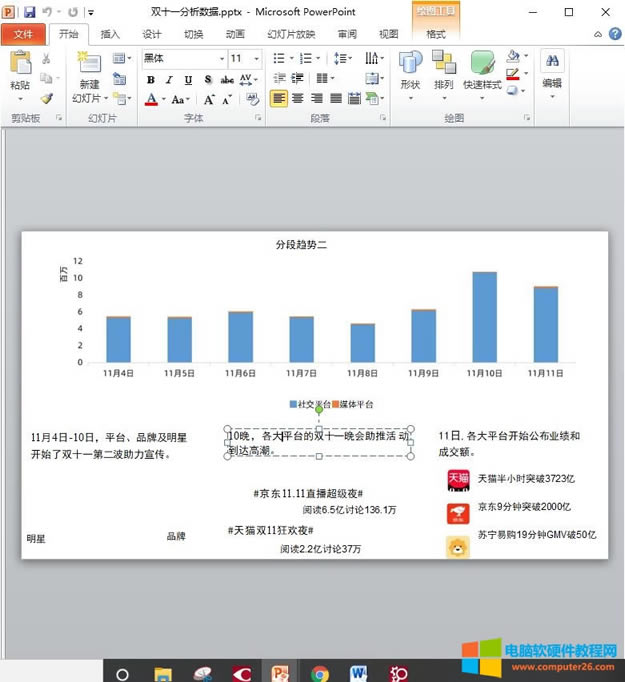
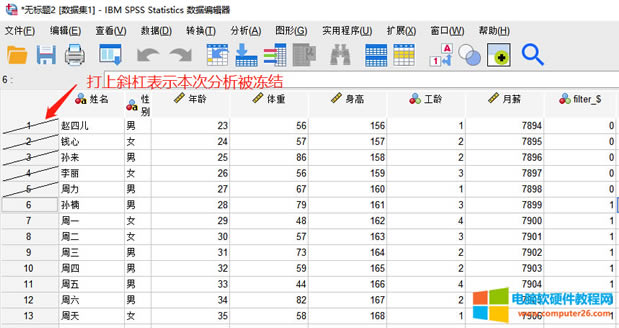
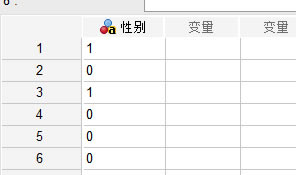
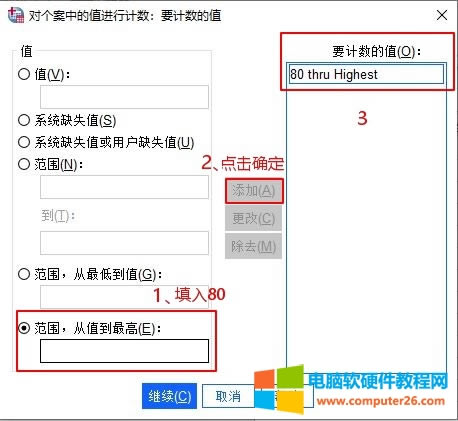
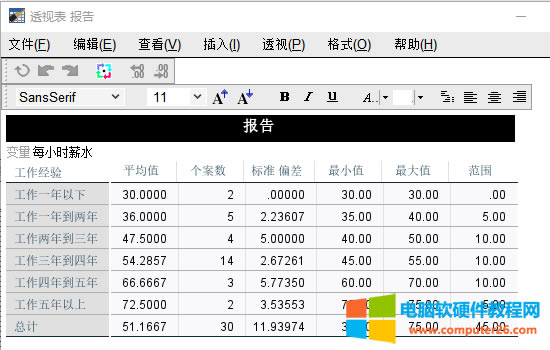
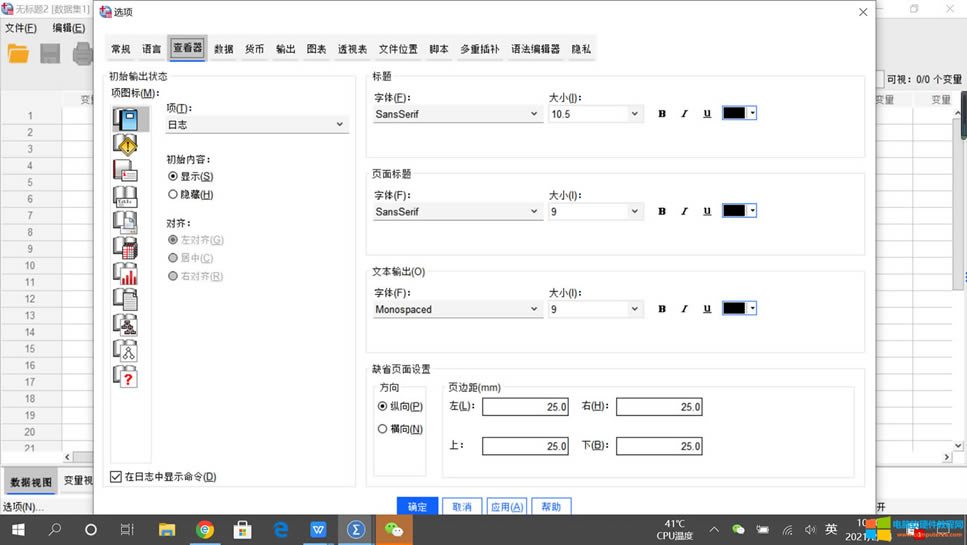

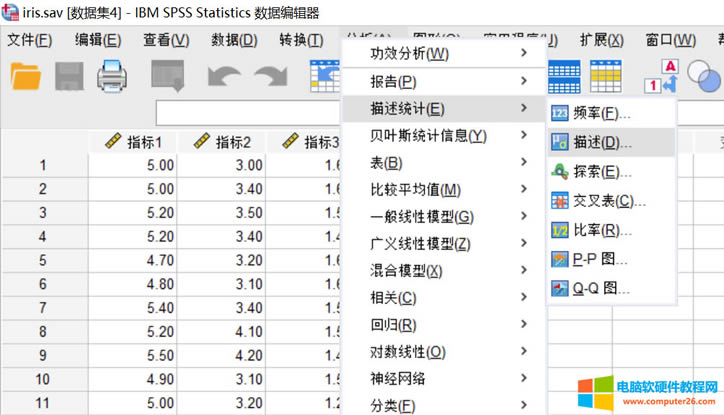
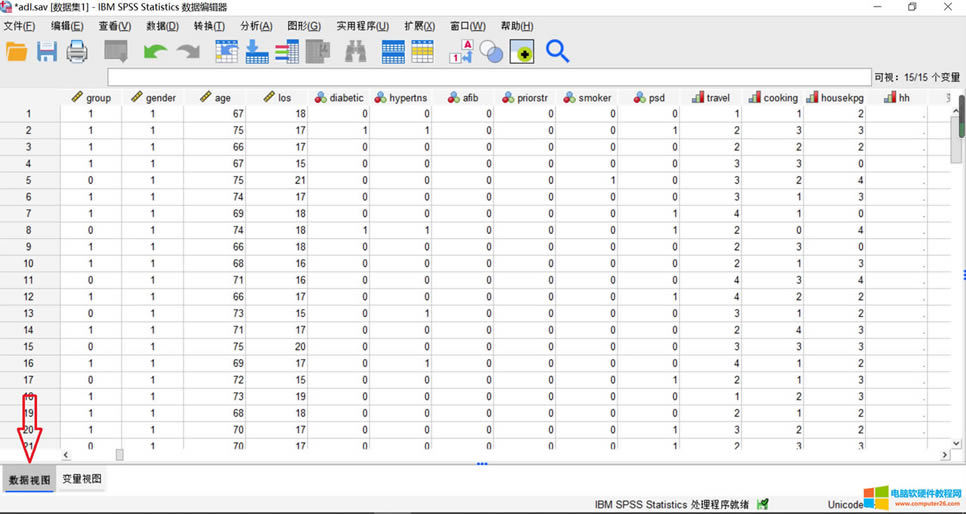
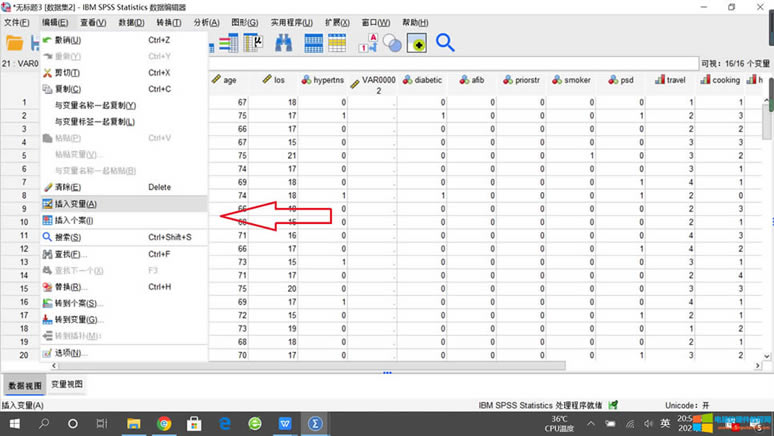
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀�ˌW(xu��)��(x��)�yԇʹ�ã�Ո�����d��24С�r��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y(t��ng)���dվ �֙Cվ �P(gu��n)�ڱ�վ
