|
�����\�еĭh��������ϵ�y���Է֞��������ϵ�y���֙C����ϵ�y������������ϵ�y��Ƕ��ʽ����ϵ�y�ȡ�
��һ���ǾwՓ����Ҫ���Y�˼��g����. �������ҵ���x�У������е�һЩ������W�߁��f�Ƿdz����Ѻõģ��Z�ԽM����߉Ҳ�ܲ�кܶ���ֵĆ��~���]�н��. �Ҳ�֪�����Ƿ�� �����������߷��g�����_�����Ԟ��������@Щ���ݣ���ֻ���Լ��z��һ����Ϣ��Ȼ�����@����ҵ����⣬�Ա��S�r���ԅ���. ��������һ������ČW��Ҳ�ܷ���. . ������߀�����֣�߅��߅������ˌ�ijЩ�����������܃H����ë������ƫ�����S���Ҳ���������⣬�Ҍ��^�m�����@һϵ������. ͬ�r����Ҳϣ�����ЌW��������u��ָ�����Ա�һ�����͌W��. �������������������������������������օ^�������������������������������������� ��x���������˃ɂ����µĕr�g. �l�F�@�����_����һ���dz��õĕ����������_�����m�ϳ��W��. ���M�ܱ����ǽ��^���������ģ�����Takanoya߀�nj�KDD�M���˿��w���������@֮���Ժ��β�����������������룬��������x�ߛ]���_���@һˮƽ. �鿴ժҪ�����������п����dz����µ�Ԓ. ������x�����r����߀������S����ֵ����~. �W���˺ܶ��㷨���һ��^���˿��@�������_����ͬһ����. ���ǣ�������Ȼ����һЩȱ��. �������������ķ��g�]�е�λ�����ұ������ѽ����^���ˣ��ڶ����Ǖ��е�ijЩ�ط������F�e�`�������e�`�����͔����e�`. �����ā��f���@Щ�e�`����Ӱ���x. ���h�x������x�����r��x�������Ϣ���W���㷨�����ھ�����c���g���Ա�����x�����������˜\. ��ϵ��������������x�����r����һЩ�Pӛ����������J�鲻�Ǻ��˽�ĕ��е�һЩ����������߀�����һЩ������ͨ���㷨. ��Ȼ�����ڻ��W���ѽ��ᵽ�ܶ����£�������Ҳ���Լ��Ŀ���. ���������и��õĽ�ጣ��қ]�ІΪ����������ֻ����x�@Щ������. �ҵ�ϵ�����µę����DZ������a��ͅ�������. �҂���ʲôҪ�M�Д����ھ� �@�����ڱ����в������{�����ھ��Dz����H���õ����}. ԓ�W�Ƶ���Դ�Ͱlչ��������ď�������. ʲô�ǔ����ھ� �������ھ�һ�~���H�ϲ����ܜʴ_��ӳԓ�W��. ���ʴ_�Ķ��x��ԓ��KDD��KDD: �е�֪�R�l�F�����@�ǏĔ������ھ���Ѓrֵ��֪�R����Ҫ�eע��. ���ң������ھ���һ���B�m���^�̣� �� ��������һ���Ե�. ��Ȼ���@�������~���Ѓrֵ�ģ��кܶ�N���⣬�@�ﲻ٘����ֻ�˽�. �������ڸ��Nԭ���҂������fͨ���g�Z�������ھ���ָ�� KDD�� �͔����}��֮�g�ą^�e ���P�@�ɂ����������ͅ^�e��Ո��ҊZhicheng Chen Cheng���@�����}�Ļش�. �͔����}��֮�g�ı��|�^�e��ʲô�� ���У����P�����}��ĸ�����Ϣ. �����}���Ŀ���Ǟ�Q���ṩ����֧��. �Q��Ԓ�f���������ò����ژI�գ��������ṩ�����C���Ԏ��������������Q��. ��ˣ������惦�Ķ�������Դ�@�õĴ����M������. �@�����˼������ĽM����ζ�������}��Ĕ����Y��. �͔����}��֮�g��ʲô�^�e�� ���H�ϣ�����֮�g����Ҫ�^�e���ڔ����Y���� �еĽ�ģͨ����ѭ������ʽ�������}�콨ģ�����ض��ķ�ʽ��ͨ��ʹ�ö�S��ģ�����ͣ�ѩ���ͣ�. �����}��ʹ���@Щ��ģ������ԭ���Ǟ��˷���OLAP�Ľ�������߽yӋ��ԃ��.
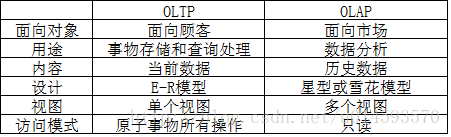
̹�ʵ��f��ͨ���Ĕ����}���ǽ������ϵģ����Ǽ��g��ʹ�Ås������ͬ. ���ܛ���aƷ���H����һ���Pϵ��������ڬF�ھͲ�������. �����������������_�ģ�������: ORACLE��MS SQL SERVER�ȣ���һЩ����֮̎������Teradata��. ���@��҂��������������������w�ą���. ���@���һ����=. �҂��γ�����������뷨. �J�R�������}���Д�������ʽ��һ����S�������� �� �����H�ϣ���������ˣ� �� ���@����������뷨. ��������ҿ��������r���ҿ���Խ�࣬��r��Խ��. �һ��˺ܶ��r�g��Ū���. ���H�ϣ��ڇ��C�Ĕ����}���Л]���������w�@�ӵĖ|��. ���@���|����ԭ����ȫ�Ǟ��˴��M�҂�������. �@�_����һ����Ŀ�. = �ðɣ��������惦�ڔ����}���еĔ����Ƕ�Sģ�ͣ�ͬ�ӣ�Ҳ���ǔ��������w��������. ��ˣ����e�m����OLAP������̎���� OLAP���@��������һ���¸���. �䌍�@������Ҳ����������. ���Ķ��x���@�ӵ�: ����̎��OLAP��һ�Nܛ�����g����ʹ�����ˆT�܉���٣�һ���ҽ������^������������Ϣ���������˽┵��. �҂��м���һ���@�����x�����@����������. �҂����ԏ��a�@�ӵ���r: �������У���һ�����ص������w�������w�ǔ�����Ư�������У�����������]���ˣ������͵��@���^���@���£�ϣ���������ҵ�һЩ�|��. . �����̎��ʧ�ؠ�B�����Կ����p�ɵ��ƄӲ��IJ�ͬ�ķ���ͽǶ��^�������w. �������������L�Ӷ�S�����������£��Բ鿴������Ϣ. ���@���f��ÿ���˶���ԓ�܉����� �����Ǻ͔����}��ı��^�D.
�����ھ�IJ��E��ʲô�� �P�ڔ����ھ�IJ��E�������ڕ��л�Internet�Ͽ����S��汾. էһ���������X������������ͬ�������H�ϣ�һ�㲽�E����ͬ��??���H�ǎׂ����E�������@Щ��ͬ�İ汾���ض����E�������ͼ���������Dz�ͬ��. �ҙz���˺ܶ���Ϣ�����J�����°汾����m. 1. �������x�� �˲��E�ľ��w������: ��������Ŀ�ģ�����������������蔵����������Ȼ���x���m�����ռ��������ռ��M����Ҫ��Ĕ��������������惦��. ͨ�����������ѽ����ڻ�����֪����Ϋ@ȡ�������磬�������Լ�����һ���ь����ԏ�Internet�ь����������߿���ʹ���������ѽ��l���Ĕ�����. ��Ҫ����Ҫע�⣬�����ռ��������^�̵ĵ�һ����Ҳ�ǻ��A���E. �@һ������Ҫ�� �� �����������x���ڔ����ھ�ģʽ�Ƿ���Ȥ���P��Ҫ. ���磬�������Ŀ���Ƿ�����ˎ�ИI�Ĕ������������ڏ������ИI�ռ���������ô�Y����.........���M��Ҳ�S����һЩ���⣬���@�������Ъ��Ŀ�����̫С. ����Σ����ں����������x����m�Ĕ����惦���픵���}�����P��Ҫ. 2. �����A̎�� ��1���������� �е�ijЩ������������ijЩ���dȤ�Č���ȱ�ٌ���ֵ���������Ҫ���������Ԍ����������_��һ�µĔ�����Ϣ�惦�ڔ����}����. ��t���ھ�Y�����o�����˝M��. ��2���������� ߉�ϻ������ϼ����ˁ��Բ�ͬ��Դ����ʽ�������Ĕ������Ԟ���I�ṩȫ��Ĕ�������.
��3�������p�� ����������ָ�����̶ȵغ�����������ͬ�r���M���ܱ���������ԭʼ���^����ɴ��΄յı�Ҫǰ���������ھ��΄ղ���Ϥ���ݵă���. ������������ͬ�r�M�ИI���\�I�����ھ�. ͨ���ܴ�. �����s�����g�����ګ@ȡ�������ļs����ʾ. ���mȻҪС�ö������ھ�����c���g��������Ҫ����ԭʼ�����������ԣ�����߀ԭ��Ĕ����ھ�Y���c߀ԭǰ�Ĕ�����ͬ�����ͬ. ��4�������D�Q�͔����xɢ�� ͨ�^ƽ���ۺϣ�����������Ҏ�����Ȍ������D�Q���m���ڔ����ھ�Ĕ���. ��Ҫ��һ��. 3. ���������㷨 �@�����҂����f�Ĕ����ھ��ض��Ĕ���̎��. �Ժ���ӑՓ. 4. ģ���u�� �ĘI�սǶȿ����ИI������C�˔����ھ�Y���Ĝʴ_��. ���H�ϣ�����һ����Ҫ�ИI���ҁ�. �籾���_�^�����������ھ��H����һ��ƫ���H���õ����}. ��ͨ���c�ض������ИI�o��ϵ. ��ˣ��҂�ͨ�^�����ھ�@�õĽYՓ���A�y������o�˽�ԓ�ИI���ˁ���һ�²��_���Ƿ������x. 5. �Y���@ʾ ͨ�^�����ھ�@�õķ�����Ϣ�Կ�ҕ��ʽ�ʬF�o�Ñ�����������֪�R�惦��֪�R���У����������ó���ʹ��. �����г����^��ֻ�ǔ����ھ������һ���^��. ���������Ŀ����Ҫ���ԓ�^��. �@�ԓ�eע��: �����ھ��^����һ�������^��. ���ÿ�����E��δ�_���A��Ŀ�ˣ��t��Ҫ������һ���������{��������. ����ʹ����Щ��͵ĈD���� ����ʹ����Щ��͵ĈD�������H�ϣ��ھ��Ŀ����ʲô��������Kϣ���õ�ʲô�����Ԉ�����Щ��ʽ�IJ����� �@�ģʽ�ĸ����кܺõ�����. ����ǰ߀���˽�ģʽ�ĸ��ֱ����6�²Ō����M����� �˲��E�������S���¸���Ҍ�����@Щ����. ��������: �䶨�x����: ʹ��Ŀ�˔�����һ�������������M�п��Y.
�����@������. ���磬��������1,000��Ӌ��C���x������. Ȼ�������ԏ��@Щ��������ȡ����������R�������s���@�ӵĔ���: Ӌ��C�Ǿ����T���Z�����wϵ�Y���ęC��. ����̎�o����ʾ�����ܲ��Ǻ����_��ÿ���˶���Ҫ�����京�x����˲��������о�=. =�� ��һ�������ǣ�һ�����e��ª����1000�l�������������ij�ª�̶�. Ȼ������ȡ����֮���҂������@���f. ����ª�������y��. ���H�ϣ�ÿ���˶���ԓ�܉��뵽��. ������������ҪĿ�đ�ԓ��Ҏ��������. ̹�ʵ��f�����ڱ���ԭʼ����������ͬ�r�pСԭʼ�����Ĵ�С. �����^�e: �䶨�x���@�ӵ�: �����^���nj�Ŀ�˔��������һ�������cһ����������Ȍ����һ�������M�б��^. �@�����x���^�L�����Ǻ���������. ��һЩ�������˽� �ϻ���؈����؈�Ƅ����������֮�g���Ѕ^�e�ģ���ô����֮�g��ʲô�^�e�� �ź�QQ���Ǽ��rͨӍ���ߣ���������֮�g�Ѕ^�e������������ʲô�^�e�� ��ˣ������^�e���H�Ϻ���������. ̹�ʵ��f�����Dž^�փɂ���ͬ�Ė|��. Ȼ���҂�ͨ���^�փɼ����H�����ڿ������IJ�ͬ���|������. ��ˣ���������c��������֮�g���Pϵ���H�Ϸdz��ӽ�. �l��ģʽ �l��ģʽ�Ķ��x���@�ӵ�: ����ָ�l�����F�ڔ����е�ģʽ. �l��ģʽ����ͺܶ࣬�����l��헼����l�������к��l���ӽY��. �@���������s�������H�Ϸdz�����. �l���Ŀ�����H�Ͽ���������l�����F������ļ��ϣ����������ţ�̣�ơ�ƺ������l���Ŀ��. �l���������ǽ������F������. ���磬ُ�I��ӮaƷ�����ͨ����: �_ʽӋ��C-���Pӛ��Ӌ��C-�֙C-�����C��. �����Б�ԓ�����l��. �ĸ��V�������x���v���l�����ӽY�����l�����Ŀ�����l���������У����Ҿ��и�������̶�. ���磬ُ�I�_ʽӋ��C����Щ�˿��ܕ�ُ�I������һ����ӮaƷ�ĹPӛ����X������Щ�˿��ܕ�ُ�Iƽ����X. ����г��@Щ���ݣ��t�����γɘ��D֮Ĕ����Y��. �����о��@Щ����֮�������l�F�S������֮�g�����P���P. ��ͻؚw ��ͻؚw�ĸ�����y���.
��֧�������C����. ��ͻؚw���}����Ҫ����Ӗ���ӱ��ҵ���ֵ����g��x��. �ؚw���}��Ҫ����: �o��һ����ģ�ͣ�Ȼ�����Ӗ�����Ɣ��������ݔ��y���������Ƕ���. Ҳ�����f��ʹ��y = g��x���Ɣ��c�κ�ݔ��x������ݔ��ֵ. ����}��: �o��һ����ģʽ����Ӗ�������Ɣ���䌦����e������: + 1��-1��. Ҳ�����f��ʹ��y = sign��g��x�����Ɣ��c�κ�ݔ��x������e. ��֮���ؚw���}�ͷ���}�����|��ͬ��Ψһ�ą^�e��������ݔ��������ͬ. �ڷ���}�У��H���Sݔ�����Ãɂ�ֵ���ڻؚw���}�У�ݔ������ȡ�κΌ���. ��ͻؚw֮�g�ą^�e��ݔ��׃�������. ����ݔ���Q��ؚw���B�m׃���A�y�� ����ݔ���Q�����xɢ׃���A�y. ����: �A�y����Ě�ض��٣��@��һ헻ؚw�΄գ� �A�y�����Ƕ��ƣ�����߀��������һ헷���΄�. ���H�ϣ��҂����f���g�Z��ָ����ֵ�A�y��˺��A�y. ���@��҂����ԕ��r����ֵ�A�y�����ؚw����e�˺��A�y�������. ��֪���Ҍ������Ɇ�. Ո�����@��. ������Ľ���У����F�˶��Z���o����ʽ��. �@���ᵽ��ģʽ��ָģ�ͣ�������Ҏ�t���Q�ߘ䣬���W��ʽ���W�j. �Ժ����f. ��Ⱥ���� ���^�ļ�Ⱥ���Ⱥ�ľۼ�������ǔ�������ļ���. ���S����r�£�һ�_ʼ�͛]�И˺���������˿���ʹ�þ���������ɔ����M��˺�. ����Еr�Q��ָ��ָ��������ͬ�������˷ֽM��Ȼ���@Щ����ƽ�����γɡ�������������. ���ϵ�yͨ������ͨ�^�o�B������ƵČ���֞鲻ͬ�ĽM�������Ӽ����Ա�ͬһ�Ӽ��еijɆT����������ƵČ���. ijЩ�ṩ����ʹ��Ⱥ����ֱ���ṩ���P��ͬ�L���߽M��͑��M�������Ĉ��. ����㷨�ǔ����ھ�ĺ��ļ��g֮һ. �����������㷨�����⣬�����߀�������������ھ��㷨�����������㷨���A̎�����E. �ژI���У�����Ԏ����Ј������T�����M���Ѕ^�ֲ�ͬ�����M��Ⱥ�w�������Yÿ�N������M�ߵ����Mģʽ�����M���T. ���锵���ھ��ģ�K�������������l�F�зֲ���һЩ�����Ϣ�ĆΪ����ߣ�Ҳ���Ԍ�ע���ض�e���M���Mһ�����������Yÿ��e�Ĕ�������. �xȺ���� �@����������. �������п�����һЩ��������. �����c������һ���О��ģ�Ͳ�һ��. �@Щ�����Ǯ���ֵ. ��������ֵ���ܕ����®�����������ի@. �õģ��������g�Z�����M�н��. �҂��ص�ԭ���Ć��}. �҂������ڔ����ھ�����ʲô�����H�ϣ�̹�ʵ��f���҂����J�锵���ھ�ֻ���Ѓɂ�����. һ���������Թ��ܣ��������ڵĹ��ܣ�����һ�����A�y�Թ��ܣ��A�y��δ֪���Ɣࣩ. �������棬�������M����Ԕ����������������������. �@��]��̫��Ҫ�f����
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y �֙Cվ �P�ڱ�վ