|
�����\�еĭh(hu��n)��������ϵ�y(t��ng)���Է֞��������ϵ�y(t��ng)���֙C����ϵ�y(t��ng)������������ϵ�y(t��ng)��Ƕ��ʽ����ϵ�y(t��ng)�ȡ�
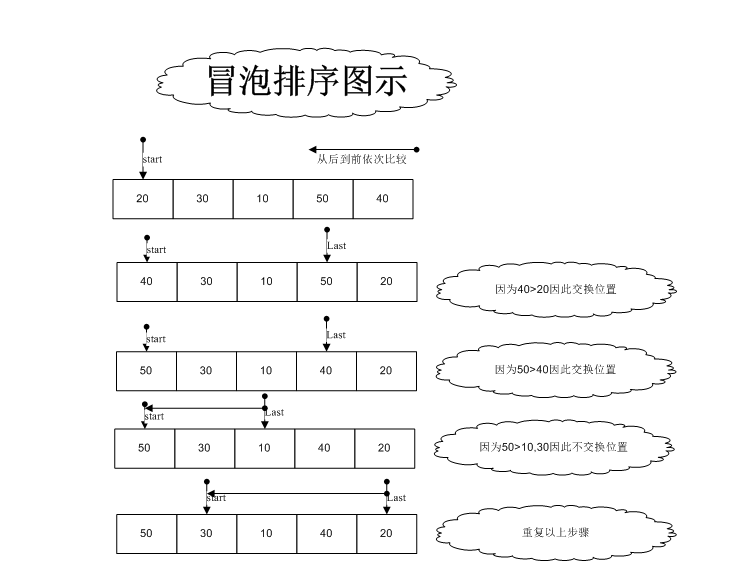
����ǰ�ɂ�������Ԕ����B�ˡ������㷨�W����朽��б����oǰ����(ji��)�c���Ԍ��Fð�����������㷨�W����朽��б��Ԍ��Fð�������I�ȹ�(ji��)�c����朱��c������(ji��)�c�ͷ�������(ji��)�c���F��ĭ�����҂�������б�����ĭ������һ���������˽�. ���죬�҂���ʹ�Û]��ǰ����(ji��)�c�ķ�ѭ�h(hu��n)�p朱�팍�F��������. ��̎���^���У��@�N���ݱ�ǰ�ɷN�����Σ�����Ч. ���a���ς���. ���Ĵ��a����: //ð������
Node *BubbleSort(Node *pNode){
int count = sizeList(pNode);
Node *pMove;
pMove = pNode;
//��v����count-1
while (count > 1) {
while (pMove->next != NULL) {
if (pMove->element > pMove->next->element) {
int temp;
//�@��Ĕ������Q�Ȇ�朱�����
temp = pMove->element;
pMove->element = pMove->next->element;
pMove->next->element = temp;
}
pMove = pMove->next;
}
count--;
//�ٴλص�朱��^��
pMove = pNode;
}
printf("%s������(zh��)�У�ð���������\n",__FUNCTION__);
return pNode;
}
�r�g: 03-03 �˺�:
-> C���F���^��ֵ����β��ֵ���혋��һ���o�^ѭ�h(hu��n)朱����o�^��(ji��)�c�� �ڌ��Hʹ���У��p朱��Ȇ�朱����ӷ�����`��. ���ڲ���ǰ����(ji��)�c�ğo�h(hu��n)�p朱��Ļ�������������
�����㷨�W��朽��б��Ԍ��Fð������ ����ǰ�IJ���<�����㷨�W��-��������>�У���ֻ�nj��F�ˌ����M���ښ�������Č��F. �ڴ˲����У��҂������F���ʹ��朽��б��M�������H�ϣ����w˼·����ͬ��. ʾ�����a���ς���: . ԓ�㷨��������: ��1�����^��������ǰ��ăɂ����������ǰһ���������ں�һ���������t���Q�ɂ�����: ��2�����@�N��ʽ�����M�ĵ�0�������D�Q��N-��v1��������c�Z�Ԇ�朱�ð�����������Ĕ������_���һ��λ�ã�����N-1��λ�ã��³���.
JavaScript�����㷨�W��1: �o��������S�C���M �o����ǎN���������㷨�ČW�����֣����˴��M��ͬ�㷨�Ľy(t��ng)һ�yԇ����(chu��ng)����һ���µ��o�����Ҫ������: ����ָ���L�ȵ��S�C���M���ṩһ����ӡݔ�����M�����Q�ɂ�Ԫ�أ��ȵ�. ���a����: function ArraySortUtility��numOfElements��{this.dataArr = []; this.pos = 0; this.numOfElements = numOfElements; this.insert =����; this.toString = toString; this.cle �����㷨�W���������� ð���������҂��W���ĵ�һ�������㷨. ����ԓ���J������ε�. ��õ������㷨. �oՓ���. �W�����Dz��ɱ����. ���죬�҂���ʹ��C�Z�Ԍ��Fԓ�㷨. ��ʾʾ�����a���ς���: �㷨�f������: ��1�����^����ǰ��ăɂ�����. �ٶ���ǰ�Ĕ������ں���Ĕ������t���Q�ɂ�����: ��2���@�ǵ�һ��. ��0������N-1�����ı�vһ��. ���Ĕ��������_���һ��λ�ã�ԓλ����������N-1��λ�ã��³���. ��3�� ���ڽ����㷨�W����؝���㷨 ؝���㷨Ҳ���ڽ�Q��(y��u)�����}. �c�ӑB(t��i)Ҏ(gu��)����ȣ�ʹ��؝���㷨������Q�S�����}����ʹ��؝���㷨�����ܽ�Q���Ѓ�(y��u)�����}. ؝���㷨��ÿ���Q���c�ڮ��r��������x��. ؝���㷨���OӋ���E: 1.����(y��u)�����}�D�Q��: �ڌ����M���x��֮�H��Ҫ��Qһ�N��ʽ���ӑB(t��i)Ҏ(gu��)����ʣ���S�����}��Ҫ��Q��2.�C��؝���x�����������ʼ�K��һ��ᘌ�ԭʼ���}����ѽ�Q������Ҳ�����f��؝���㷨ʼ�K�ǰ�ȫ��. 3.������؝���x����C��֮�������ӆ��}�M���������|: �(y��u)������c؝���x��Y���ԫ@��ԭʼ���}���(y��u)�⣬�Ķ����̶ȵؽ�Q ͨ�^�����㷨�W���ĺ����������������x������ֱ�Ӳ������� һ��. �������������������������㷨�����s�Ȟ�O��N ^ 2���������˼����: ����Ͷ˵Ĕ����_ʼ��Ȼ������^. Ȼ�Q. ���a����: / *�������ð������* / void BubbleSort1��int n��int * array��/ * little> big * /��int i��j; for��i = 0; i
�����㷨�W��-�H���Fһ�εĵ�һ���ַ� �@Ҳ�ǡ�����Ҫ�s���зdz��������ԇ���}. ���}������: �����ַ����ЃH���Fһ�εĵ�һ���ַ�. ���ݔ�롰 abaccdeff�����tݔ���� b��. һ�_ʼ��ÿ���˶����J����εķ��������L��ÿ���ַ�����^���������δ�ҵ���ͬ��Ԫ�أ��tԓԪ���ǃH���Fһ�εĵ�һ���ַ�. ���s�Ȟ�O��n ^ 2��. �@Ȼ�@��Ч�ʲ���. �@�����}�Ŀ��w������һ�����}�����㷨. ��Ҋ�������㷨��������������M��������ϣ����. ���m�ϴˆ��}. �@��һ����ϣ����. ���ȣ��҂����Խ���һ��256�L�ȵĔ��M �����㷨�W��-��ӡ�ɂ�朱��ĵ�һ��������(ji��)�c ����朱��Ĺ�����(ji��)�c�ǽ�����㷨���}���@�������y. �҂���Ҫ֪�����ǣ�һ���ɂ�朱�����һ��������(ji��)�c����ô�ɂ�朱����Π���ǡ� Y����ͣ�Ҳ�����f��ԓ������(ji��)�c֮������й�(ji��)�c������ͬ��. ����: ���H�ϣ�ֻҪ����һ���@���DƬ�����F�ͷdz�����. ���ȣ��҂��քe��v�ɂ�朱������քe�@���������L��L1��L2. . Ȼ���ڌ��ҹ�����(ji��)�c�r��������| L1-L2 |. ���L朱��У����ɂ�朱�ͬ�r����v���Д�ÿһ����(ji��)�c�Ƿ���ͬ. �����ͬ���t�ҵ���һ��������(ji��)�c. �����Ĵ��a���ς��� �����㷨���ڔ��M�п����ҵ��ɂ����ֲ��������������_��һ��ֵ ���㷨����������: �����ҵ����M�еăɂ����֣���ʹ�@�ɂ����ֵĺ͵��ڽo��ֵ. Ŀǰ���Ҽ��O���M���Dz���ȵ�����. �@�����}��������ԇ�І���. ���ڷN�Nԭ���қ]�лش�c�Z�Ԇ�朱�ð���������@�܌���. �䌍���@�����}�ܺ��Σ��҂���һ�N���^����ķ����팍�F. ע�ⲻҪʹ�ÃɌ�ѭ�h(hu��n)��Ԫ�ر�v. ʾ�����a���ς���: . ԓ�㷨����������: ��0�����Ȍ�ԭʼ���M�M��������ʹ��ɞ��������M: ��1�������M�^i [0]�͔��Mβj [n-1]�M������ |
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I(y��)��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y(t��ng) �֙Cվ �P�ڱ�վ