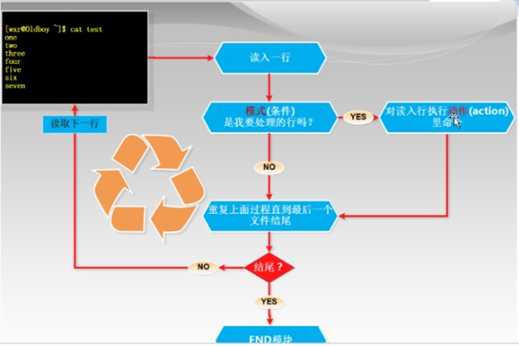
|
�����\�еĭh��������ϵ�y���Է֞��������ϵ�y���֙C����ϵ�y������������ϵ�y��Ƕ��ʽ����ϵ�y�ȡ�
-W������--help��-Wʹ����r��--usage ��ӡ����awk�x헺�ÿ���x헵ĺ����f��. -W�q��--lint ��ӡ���P�o����ֲ�����yunixƽ�_�ĽY���ľ���. -W�fƤ��--lint�fƤ ��ӡ���P�o����ֲ�����yunixƽ�_�ĽY���ľ���. -W posix ���_����ģʽ. ���ǣ��������������ƣ��o���R�e: \ x��function�P�I�֣�func���D�x���У����Ү�fs�ǿո�r�����������ֶηָ������\���**��** =������Q^��^ =; fflush�oЧ. -W�����g����--re-inerval ���Sʹ���g�����t���_ʽ��Ո��醣�grep�е�Posix�ַ�������緽��̖���_ʽ[[: alpha: ]]. -WԴ�����ı���--source�����ı� ʹ��program-text����Դ���a�����Ԍ����c-f������ʹ��. -W�汾��--version ��ӡ�e�`�����Ϣ�İ汾. awk�_����ģʽ�Ͳ����M��: ģʽ{action}������$ awk'/ root /'�yԇ��$ awk'$ 3 <> ���߶��ǿ��x��. ����]��ģʽ���tԓ����������������ӛ�. ����������κβ������tݔ��ƥ������ӛ�. Ĭ�J��r�£�ÿ�lݔ���ж���һ�lӛ䛣������Ñ�����ָ����ͬ�ķָ�������RS׃���M�зָ�. ԓģʽ��������������һ�N: ԓ������һ���������������ͱ��_ʽ�M�ɣ��ÓQ�з����̖���_����λ�ڻ���̖��. ��Ҫ�����Ă�����: Table1.awk�h��׃�� ׃������ $ n ��ǰӛ䛵ĵ�n���ֶΣ���FS�ָ�. $ 0 ���ݔ��ӛ�. ARGC �����Ѕ�����. ARGIND ��ǰ�ļ����������ϵ�λ�ã���0�_ʼӋ����. ARGV ���������Ѕ����Ĕ��M. CONVFMT �����D�Q��ʽ��Ĭ�J�飥.6g�� ENVIRON �h��׃�����P���M. ERRNO ���һ��ϵ�y�e�`������. FIELDWIDTHS �ֶΌ����б����ÿո��I�ָ���. �ļ��� ��ǰ�ļ���. FNR �cNR��ͬ���������ڮ�ǰ�ļ�. FS �ֶηָ�����Ĭ�J���κοո�. IGNORECASE �����true���t�oՓ��С��ƥ�䶼��������. NF ��ǰӛ��е��ֶΔ�. NR ��ǰӛ�̖.
OFMT ����ݔ����ʽ��Ĭ�J�飥.6g��. OFS ݔ���ֶηָ�����Ĭ�J��ո�. ORS ݔ��ӛ䛷ָ�����Ĭ�J��Q�з���. �L�� ��match����ƥ����ַ������L��. RS ӛ䛷ָ�����Ĭ�J��Q�з���. RSTART ƥ�书��ƥ����ַ����ĵ�һ��λ��. SUBSEP ���M�˷ָ�����Ĭ�J��\ 034��. ��2. �\�I�� �����T�f�� = + =-= * = / =��= ^ = ** = ���� C�l�����_ʽ || ߉�� && ߉�c ??�� ƥ�����t���_ʽ�Ͳ�ƥ�����t���_ʽ <=>> =��= ==
�Pϵ�\��� �ո� �B�� +- �Ӝp * /�� �˷������������� +-�� һԪ�ӷ����p����߉�� ^ *** �Uչ�Դ ++- ���ӻ�p��ǰ�Y���Y $ �ֶ΅��� �� ���M�ɆT awk�����ԓQ�з��Yβ��ÿһ������ӛ�. ӛ䛷ָ���: Ĭ�J��ݔ���ݔ���ָ��������܇�������������ڃ���׃��ORS��RS��. $ 0׃��: ����������ӛ�. ���磬$ awk'{print $ 0}'�yԇ���ڜyԇ�ļ���ݔ������ӛ�. ׃��NR: Ӌ����. ̎��ÿ��ӛ䛺�NR��ֵ����1. ����awk���M�L����$ awk'{print NR��$ 0}'�yԇ��ݔ���yԇ�ļ��е�����ӛ䛣�����ӛ�ǰ�@ʾӛ�̖. ӛ��е�ÿ�����~���Q�顰��Ĭ�J��r���ÿո���Ʊ����ָ�. Awk���Ը�ۙ��Ĕ�����������ֵ�����ڃ���׃��NF��. ���磬$ awk'{print $ 1��$ 3}'�yԇ����ӡ�yԇ�ļ����ÿո�ָ��ĵ�һ�͵����У��ֶΣ�. ����׃��FS����ݔ���ֶηָ�����ֵ. Ĭ�Jֵ��ո���Ʊ���. �҂�����ͨ�^-F�������x���FS��ֵ. ���磬$ awk -F: '{print $ 1��$ 5}'�yԇ����ӡ��ð̖�ָ��ĵ�һ�͵����еă���. ����ͬ�rʹ�ö�����ָ���. ���@�N��r�£��ָ��������ڷ���̖�У�����$ awk -F'[: \ t]''{print $ 1��$ 3}'�yԇ���@��ζ����space��ð̖���Ʊ�������ָ���. Ĭ�J��r�£�ݔ���ֶεķָ�����ո��惦��OFS��. ���磬��$ awk -F: '{print $ 1��$ 5}'�yԇ�У�$ 1��$ 5֮�g�Ķ�̖��OFSֵ.
����������gawk�����m����unix�汾��awk. \ Y �چ��~���_�^��Yβƥ��һ�����ַ���. \ B ƥ����~�еĿ��ַ���. \ �چ��~�_�^ƥ��һ�����ַ�����Ȼ���_ʼ��λ. \> �چ��~��ĩβƥ��һ�����ַ���������ĩβ��λ. \ w ƥ����ĸ���ֆ��~. \ W ƥ��һ������ĸ���ֵĆ��~. \�� ���ַ������_�^ƥ��һ�����ַ���. \' ���ַ���ĩβƥ��һ�����ַ���. ����ƥ��ӛ䛻����е����t���_ʽ. ���磬$ awk'$ 1?/ ^ root /'test���ڜyԇ�ļ��ĵ�һ�����@ʾ��root�_�^����. �l�����_ʽ1�� expression2: expression3������: $ awk'{max = {$ 1> $ 3}�� $ 1: $ 3: print max}�yԇ. �����һ���ֶδ��ڵ������ֶΣ��t��$ 1����omax����t��$ 3����omax. $ awk'$ 1 + $ 2 <100'�yԇ.> $ awk'$ 1> 5 && $ 2 <> ����ģ��ƥ��ĵ�һ��ģ��ĵ�һ�γ��F���ڶ���ģ��ĵ�һ�γ��F��������. ����]�г��Fģ�壬�t���c�_�^��Yβƥ��. ���磬$ awk'/ root /��/ mysql /'test���@ʾ��root��һ�γ��F��mysql��һ�γ��F֮�g��������. $ cat / etc / passwd | awk -F: '\ NF��= 7 {\ printf�����ڣ�d�У��]��7���ֶ�: ��s \ n����NR��$ 0��} \ $ 1��?/ [A-Za-z0-9] / {printf�����У�d������ĸ�͔����Ñ�ID: ��d: ��s \ n��NR��$ 0��} \ $ 2 ==�� *�� {printf�����ڣ�d�У��]���ܴa: ��s \ n����NR��$ 0��}' cat���Y��ݔ����awk��awk����֮�g�ķָ����O�Þ�ð̖. �����NF��������7��Ո�������²��E. printf��ӡ�ַ�������??�Л]��7���ֶΡ����@ʾӛ�. �����һ���ֶβ������κ���ĸ�͔��֣��tprintf��ӡ���o��ĸ�͔����Ñ�ID�������@ʾӛ䛺�ӛ䛵Ĕ���. ����ڶ����ֶ�����̖���t��ӡ�ַ����� no passwd�������ӛ䛔���ӛ䛱���. BEGINģ�K������һ�������K��ԓ�����K��awk̎���κ�ݔ���ļ�֮ǰ����. ��˟o���κ�ݔ�뼴�Ɍ����M�Мyԇ. ͨ�����ڸ��ă���׃��������OFS��RS��FS����ֵ���Լ���ӡ���}. ����: $ awk'BEGIN {FS =��: ��; OFS =�� \ t��; ORS =�� \ n \ n��} {��ӡ$ 1��$ 2��$ 3}�yԇ. ����ı��_ʽ��ʾ��̎��ݔ���ļ�֮ǰ�����ֶηָ�����FS���O�Þ�ð̖����ݔ���ļ��ָ�����OFS���O�Þ��Ʊ���������ݔ��ӛ䛷ָ�����ORS���O�Þ�ɂ��Q�з�. $ awk'BEGIN {print�� TITLE TEST��}}�H��ӡ���}. END�c�κ�ݔ���ļ�����ƥ�䣬���Lj��Є����K�е����Є���������̎��������ݔ���ļ������. ���磬$ awk'END {print��ӛ䛔��顱 NR}���yԇ������Ĺ�ʽ����ӡ������̎��ӛ䛵Ĕ�. awk�еėl���Z���Ǐ�C�Z�Խ���ģ����Կ��Ƴ��������. 14.5.1.if�Z��
��ʽ��
{if (expression){
statement; statement; ...
}
}
$ awk'{if��$ 1 <$ 2��print="" $="" 2��="" too="" high��}'�yԇ.=""> $ awk'{if��$ 1 <$ 2��{count="" ++;��ӡ���_����}}'�yԇ.=""> 14.5.2.if / else�Z�䣬�����p���Д�
��ʽ��
{if (expression){
statement; statement; ...
}
else{
statement; statement; ...
}
}
$ awk'{if��$ 1> 100��print $ 1�� bad��;��t��ӡ���_����}'�yԇ. ���$ 1����100���t��ӡ$ 1�e�`����t��ӡ�_��. $ awk'{if��$ 1> 100��{count ++;��ӡ$ 1} else {count--;��ӡ$ 2}���yԇ. ���$ 1����100���t��count��1��Ȼ���ӡ$ 1����t��count��1��Ȼ���ӡ$ 1. 14.5.3.if / else else if�Z�䣬���ڶ����Д�.
��ʽ��
{if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else if (expression){
statement; statement; ...
}
else {
statement; statement; ...
}
}
awk�Д��M���˿����ǔ��ֺ���ĸ���Q���P���M. 14.7.1. �˺��P���M 14.8.1. �ַ������� 14.8.2. �r�g���� 14.8.3. ���Ô��W���� ��4. �������Q����ֵ
atan2��x��y�� ��y��x�����ȵ����� cos��x�� ���Һ��� exp��x�� �Uչ�Դ int��x�� �A�� log��x�� ��Ȼ���� rand���� �S�C�� sin��x�� ���� sqrt��x�� ƽ���� Ʒ�ƣ�x�� x��rand���������� int��x�� ���룬�]������ rand���� ����һ�����ڻ����0��С��1���S�C�� 14.8.4. �Զ��x���� ��߀������awk���Զ��x��������ʽ����:
function name ( parameter, parameter, parameter, ... ) {
statements
return expression # the return statement and expression are optional
}
ͨ������awk���ж���ݔ���ļ��r��NR == FNR�������x��. ���ԓֵ��true���t��ʾ��һ���ļ�����̎����. NR == FNRͨ�������xȡ�ɂ�������ļ����������Д��Ƿ������xȡ��һ���ļ�. test.txt 10�Ѓ��� test2.txt 4�Ѓ��� awk'{print NR��FNR}'test.txt test2.txt 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 1 12 2 13 3 14 4 �F���ЃɷN�ļ���ʽ��������ʾ: #cat���� ����| 000001 ��˼| 000002 #cat cdr 000001 | 10 000001 | 20
000002 | 30 000002 | 15 ����ĽY������ͬһ���ϴ�ӡ�Ñ�������̖�ͽ��~��������ʾ: ����| 000001 | 10 ����| 000001 | 20 ��˼| 000002 | 30 ��˼| 000002 | 15 �������´��a #awk -F \ |'NR == FNR {a [$ 2] = $ 0; next} {��ӡa [$ 1]�� |�� $ 2}'����cdr �uՓ: ��NR = FNR��true�r���Дஔǰ�����xȡ��һ���ļ�������Ȼ��ʹ��{a [$ 2] = $ 0; next}ѭ�h�������ļ���ÿһ�д惦�����Ma�У���ʹ��$ 2�ĵڶ����ֶ�����������. ��NR = FNR��false�r���Дஔǰ�����xȡ�ڶ����ļ�cdr��Ȼ�����^{a [$ 2] = $ 0; next}���o�l������{��ӡ�ڶ����ļ�cdr a [��ÿһ��] $ 1]�� ||�� $ 2}���@�r׃��$ 1�ǵڶ����ļ��ĵ�һ���ֶΣ��������xȡ��һ���ļ��r����һ���ļ�$ 2�ĵڶ����ֶ��������M��. ��ˣ��������ڴ�̎ʹ��[[1]]������ԓ���M. awk'{gsub��/ \ $ /��������; gsub��/��/��������; �����$ 1> = 0.1 && $ 1 <0.2��c1 +=""> ��t��$ 1> = 0.2 && $ 1 <0.3��c2 +=""> ��t��$ 1> = 0.3 && $ 1 <0.4��c3 +=""> ��t��$ 1> = 0.4 && $ 1 <0.5�� +=""> ��t��$ 1> = 0.5 && $ 1 <0.6��c5 +=""> ��t��$ 1> = 0.6 && $ 1 <0.7��c6 +=""> ��t��$ 1> = 0.7 && $ 1 <0.8��c7 +=""> ��t��$ 1> = 0.8 && $ 1 <0.9��c8 +=""> ��t��$ 1> = 0.9��c9 + = 1; else c10 + = 1; } END {printf����d \ t��d \ t��d \ t��d \ t��d \ t��d \ t��d \ t��d \ t��d \ t��d \ t����c1 ��c2��c3����c5��c6��c7��c8��c9��c10}'/ NEW ʾ��/ʾ��: awk'{if��$ 0?/^>.*$/��{tmp = $ 0; getline; if��length��$ 0��> = 200��{print tmp�� \ n�� $ 0;}}}'�ļ��� awk'{if��$ 0?/^>.*$/��{IGNORECASE = 1; if��$ 0?/ PREDICTED /��{getline;} else {��ӡ$ 0; getline;��ӡ$ 0;}}}'�ļ��� awk'{if��$ 0?/^>.*$/��{IGNORECASE = 1; if��$ 0?/ mRNA /��{��ӡ$ 0; getline;��ӡ$ 0;} else {getline;}}}'�ļ��� awk'{temp = $ 0; getline; if��$ 0?/ unavailable /��{;} else {print temp�� \ n�� $ 0;}}'�ļ��� substr��$ 4,20��--->��ʾ���ĵ�4���ֶ��еĵ�20���ַ��_ʼ��һֱ���m���O�õķָ����������Y��. substr��$ 3,12,8��--->��ʾ���ĵ������ֶ��еĵ�12���ַ��_ʼ���Խث@��8���ַ��Y��. һ��awk�ַ��������� $ awk'BEGIN {a =�� 100��; b =�� 10test10��; print��a + b + 0��;}' 110 ��ֻ��Ҫͨ�^�� +�������B��׃��. �Ԅӌ��ַ������ƞ�����. �ǔ���׃��0���ҵ���һ���ǔ����ַ����Ժ��ԄӺ�����. �ɂ���awk�����D�Q���ַ��� $ awk'BEGIN {a = 100; b = 100; c =��a���� b��;��ӡc}' 100100 ֻ�茢׃���c������̖�B�Ӽ����M��Ӌ��. ��awk���M�L����awk�ַ������������ַ�������朽ӣ����� $ awk'BEGIN {a =�� a��; b =�� b��; c =��a���� b��;��ӡc}' ab $ awk'BEGIN {a =�� a��; b =�� b��; c =��a + b��; print c}' �B���ļ��е���: awk'BEGIN {xxxx =����;} {xxxx =��xxxx���� $ 0��;} END {print xxxx}'temp.txt awk'BEGIN {xxxx =����;} {xxxx =��xxxx�� \����\���� $ 0��;} END {print xxxx}'temp.txt ��ȡ���ϗl�������ַ���: cat>�R�r 74938 A> G 347589B> 3795743 awk'{x = $ 0; while��match��x���� [AZ]> [AZ]��]��> 0��{print substr��x��RSTART��RLENGTH��; x = substr��x��RSTART + RLENGTH��;}}'temp awk�ַ��������������÷�ʾ��:
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y �֙Cվ �P�ڱ�վ