|
����(j��)�\�еĭh(hu��n)��������ϵ�y(t��ng)���Է֞��������ϵ�y(t��ng)���֙C����ϵ�y(t��ng)������(w��)������ϵ�y(t��ng)��Ƕ��ʽ����ϵ�y(t��ng)�ȡ�
���t���_(d��)ʽ�yԇƽ�_: ����������ڞ�Lazada�u�������M������ע���Ŀ. ������Q��CҎ(gu��)�t���ӏ�(f��)�s. Ҫ����: 1. Ӣ����ĸ��С�� 2. ��(sh��)�� 3. Խ���Z 4. һЩ�����ַ������硰��������-������ _����. ��(d��ng)�ҿ����@��Ҫ��r������Ȼ�뵽�����t���_(d��)ʽ. ��ˣ������±��_(d��)ʽ���Ա��^��ʽ������: ^��[A-Za-z0-9 ._������'\-] | [aA����???����????????????????a??????????bBcCdD??eE����????����??��??��f��??????????FFgGhHiI����????����??jJkKlLmMnNoO����????����???????????????????????????pPQQrRsStTuTu] �ڜyԇ�h(hu��n)���У��˱��_(d��)ʽ�ڹ����ϝM���˘I(y��)��(w��)����Ҫ���Ѱl(f��)�����R�������ĭh(hu��n)����. �Y(ji��)��(li��n)�C�l(f��)�F(xi��n)(li��n)�CӋ��C��CPU�j����100�����@��(d��o)������վ�c��푑�(y��ng)�ٶȮ�������. ͨ�^�D(zhu��n)�����̸�ۙ���l(f��)�F(xi��n)���о��̶����ڴ����t���_(d��)ʽ����C��:
һ�_ʼ�����y�����ţ����t���_(d��)ʽƥ���^����Ό�(d��o)��CPU׃�ߣ����ԑ��ɵđB(t��i)�������˔�(sh��)��(j��)���l(f��)�F(xi��n)С�����t���_(d��)ʽ���кܶ�����. ����ͨ�����p�ɵķ�ʽ����. ֻҪ�����܉�M�㹦��Ҫ�������͕��J(r��n)���Լ��ѽ�(j��ng)���F(xi��n)��Ŀ��(bi��o)��������ȫ�����˿������ĺ��. �[�ص�����. ��������@�N��Ѫ���е����^��Ҏ(gu��)����(z��i)�y�Ի��ݡ�. ���挢Ԕ��(x��)�����ˆ��}���Ա����؏�(f��)��ͬ���e�`.
�f���������壬�҂������t���_(d��)ʽ�����_ʼ. ��Ҏ(gu��)������Է֞�ɂ�����e: һ���DFA���_���������ԄәC������һ���NFA�����_���������ԄәC��. ������֮��NFA����(y��ng)�������t���_(d��)ʽ������(d��o)��ƥ�䣬��DFA����(y��ng)�����ı�������(d��o)��ƥ��. DFA��ƥ����ı��_ʼ�������ң�ÿ���ַ�����ƥ��ɴΣ���r�g��(f��)�s���Ƕ��ʽ�����ͨ�����죬����֧�ֵĹ��ܺ��٣���֧�ֲ��@�M�����N���ã��ȵ�. ; NFA�����t���_(d��)ʽ�_ʼ�����B�m(x��)�xȡ�ַ��ԇLԇƥ�䮔(d��ng)ǰ�����t�ԣ����³��ַ����ڲ�ƥ��r��ԇ. ͨ����r�£��ٶ��^���ҕr�g���. ��(f��)�s���Ƕ��ʽ����ĵ���r��ָ��(sh��). ����NFA֧�ָ�������ڴ����(sh��)���̷���������Java��js���У��҂������RNFA. ������ı��_(d��)ʽ�����֞����� text =������֮�� regex =�� to��nite | nighta | night���� ��(d��ng)NFAƥ��r������(j��)���t���_(d��)ʽƥ���ı�. ��tƥ��a��ʧ�����^�m(x��)ֱ���ı��еĵ�һ��t��Ȼ��o��e���^��ʧ������Ҏ(gu��)���˵�t���^�m(x��)ֱ���ı��еĵڶ���t��Ȼ���ı��е�o��oҲƥ�䣬�^�m(x��)�����t���_(d��)ʽ�������������x�l��������ƥ�䣬��һ��ʧ����Ȼ��ɂ�java���t���_(d��)ʽԔ��������ֱ��ƥ��. ƥ��DFA�r���ı�����ƥ�����t���_(d��)ʽ����a��tƥ�䣬ֱ����һ��tƥ�����tt������e����ƥ��o���^�m(x��)ֱ���ı��ڶ���t����ƥ�䳣Ҏ(gu��)t��Ȼ��oƥ��o. ��(d��ng)n�l(f��)�F(xi��n)��Ҏ(gu��)�д����������xƥ��헕r�����_ʼ����ƥ�䣬ֱ���ı��е�gʹ��һ�����x�l����ƥ���ֹ���^�m(x��)��ֱ�����һ��ƥ���. ������Ҋ����DFAƥ���^���У��ı��е��ַ��H�����^��һ��. ���³��IJ�����(y��ng)��NFA��. ���⣬�oՓ���t���_(d��)ʽ��ξ���������DFA���ı�ƥ���^�̶���һ�µģ������ı����ַ�����������ƥ�䣬���DFA��ƥ���^�����c���t���_(d��)ʽ�o�P(gu��n)������NFA���ڲ�ͬ�����t���_(d��)ʽ������ͬ�����ã�ƥ���^����ȫ��ͬ. ��ӑՓ����֮���҂�����ʲô�ǻ���. �������±��_(d��)��������ÿ���˶��dz��������D�� ab {1,3} c Ҳ�����f�����g��b��Ҫƥ��1?3��. ��ˣ������ı��� abbbc��������(j��)��1������NFA�����ƥ��Ҏ(gu��)�t�������l(f��)������. ���_(d��)ʽ�е�aƥ���bǡ����ȫƥ���ı��е�3 b��Ȼ��cƥ�䣬һ��ȫ��ƥ��. ����҂����ı����Ğ顰 abc����ô�k����ֻ���^����ĸbȱʧ�����ǰl(f��)�������^�Ļ���. ƥ���^��������ʾ����ɫ��ƥ��헣��Dz�ƥ��헣���
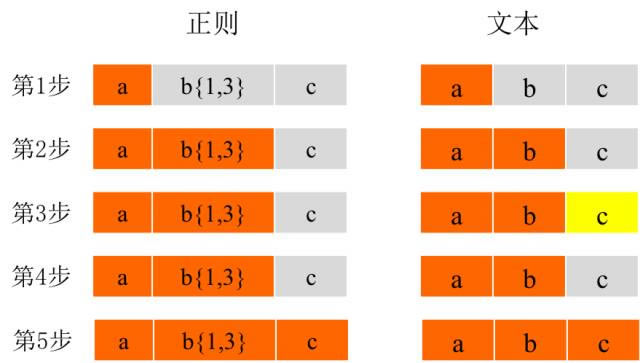
��1������2����(y��ng)ԓ���������⣬���Ǟ�ʲôҪ�ĵ�3���_ʼ���M���cb {1,3}ƥ����ı����ѽ�(j��ng)��ab�ˣ�������ĸc��b {1,3�����ϵ�����}���^�أ��@���҂����������ᵽ�ij�Ҏ(gu��)؝�����ܣ��@��ζ��b {1,3}���M������ƥ�������ַ�. ���@���ط����҂�����֪�������ƥ�䣬ֱ��ײ���ω���ֹ. ���@�N��r�£����E3�еIJ�ƥ��֮������ƥ���^�̛]����ɣ������ַ�c��ї�һ�ӱ��³���Ȼ��ʹ�����t���_(d��)ʽ�е�c��̎���ı��е�c. ��ِ. �@�l(f��)���˻���. �҂�����ʲô��؝��ģʽ.
������ÿ���˶�֪�����ʹ�����������ַ�: i. ��: ���V����ƥ���I(l��ng)���ַ�0�λ�һ��. ���H�ϣ��@��ζ���_�^�ַ��ǿ��x��. ii. +: ���V����һ�λ���ƥ��ǰ��(d��o)�ַ�. iii. *: ���V����ƥ���_�^�ַ�0�λ���. iv. {min��max}: ���V�������С�����r�gƥ��ǰ��(d��o)�ַ�. min��max�����ؓ(f��)����(sh��). ����ж�̖����ʡ����max���t��ʾmax�]������. ���ͬ�rʡ���˶�̖��max���t��ʾ�؏�(f��)��min��. Ĭ�J(r��n)��r�£��@Щ�����ַ���؝���ģ�Ҳ�����f������������(j��)ǰ��(d��o)�ַ�ƥ��M���ܶ�ă�(n��i)��. �@����˞�ʲô�ڵ�3���ֵ�ʾ���У����E3֮��l(f��)��������. �������ַ������ӆ�̖�������Ԇ��ö���ģʽ. ���@�Nģʽ�£���Ҏ(gu��)���挢�؏�(f��)�M�����ٵ�ƥ���ַ�. ƥ��ɹ��������^�m(x��)ƥ�������ַ���. �������ʾ���У���������t���_(d��)ʽ���Ğ� ? ab {1,3}��c ƥ���^�����£���ɫƥ�䣬��ƥ�䣩
���Կ������ڷ�؝��ģʽ�£���b {1,3}֮���E2�е�b�c�ı�bƥ�䣬Ȼ��ʹ��cƥ���ı��е�c��������.
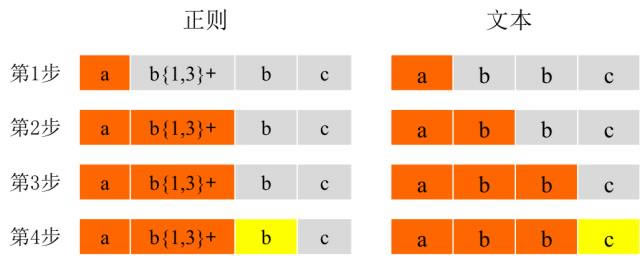
����������Ă����_(d��)ʽ֮�����Ӽ�̖��+�����t��ռģʽ�����_. ��؝��ģʽһ��java���t���_(d��)ʽԔ������ռģʽ��ƥ�����L��ģʽ. ���ǣ��ڪ�ռģʽ�£����t���_(d��)ʽ�M����ƥ���ַ���. һ����ِʧ���������Y(ji��)����ِ����������. �҂�������ı��_(d��)ʽ������ ? ab {1,3} + bc ����҂�ʹ���ı��� abbc����ƥ���������_(d��)ʽ���tƥ���^��������ʾ����ɫ��ƥ��헣��Dz�ƥ��헣���
���l(f��)�F(xi��n)���ڵ�2���͵�3���У�b {1,3} +�c�ı��еăɂ���ĸbƥ�䣬���Y(ji��)���ı��ЃH����һ����ĸc. Ȼ���ڵ��IJ��У���Ҏ(gu��)�ı��е�b�c�ı��е�cƥ��. ����o��ƥ�䣬�t����(zh��)�л���. �˕r�������ı��o���c���t���_(d��)ʽƥ��. ����h�������t���_(d��)ʽ�еļ�̖��+�����t�����ı�ƥ��. �г��������Nģʽ�ı��_(d��)ʽ��������ʾ: ؝�� �ж� ���� X * X * +
X + X ++ X {n} X {n}�� X {n} + X {n��} X {n��}�� X {n��} + X {n��m} X {n��m}�� X {n��m} + �F(xi��n)�ڻ��һ�±����_�^�ĺ��L�����t���_(d��)ʽ�����H�ϣ���(j��ng)�^������������һ������
���_(d��) . �ַ�����С�s��250��+̖��ʾԓ�ַ������ٳ��F(xi��n)һ��. ����(j��)����NFA�����؝��ģʽ����(d��ng)�Ñ�ݔ��һ���^�L���ַ������M��ƥ��r��һ���l(f��)�����ݣ�Ӌ�������ܴ�. ����������˪�ռģʽ��Ҳ��Q��100��CPU���}.
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀�ˌW(xu��)��(x��)�yԇʹ�ã�Ո�����d��24С�r��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ(f��)��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y(t��ng) �֙Cվ �P(gu��n)�ڱ�վ