|
�����\�еĭh��������ϵ�y���Է֞��������ϵ�y���֙C����ϵ�y������������ϵ�y��Ƕ��ʽ����ϵ�y�ȡ�
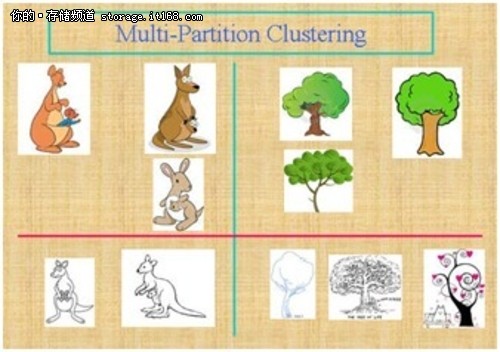
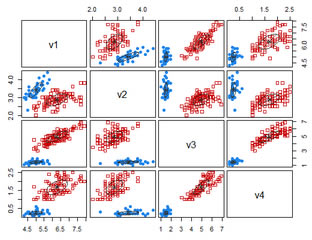
��Ⱥ������CA����һ�N���͵ğo�O���W������. �˷����������������������֞鲻ͬ�ĽM. ��һ�M����ֽM�����ƌ�����^�̷Q����. �. Ⱥ����ͬһȺ���б˴����Ƶ��c����Ⱥ���еČ������ƵĔ�������ļ���. һ�M�����������ҕ��һ�M����˾����Ҳ����ҕ��һ�N�������s��ʽ. �M�ܷ���Dž^����M��e����Ч�ֶΣ�������ͨ����Ҫ���F���ռ��͘�ӛ����Ӗ��Ԫ�M��ģʽ�����ҷ����ʹ���@ЩԪ�M��ģʽ��ÿ���M�M�н�ģ. ����һ�N�o�O���ČW��������������@������Ȼ�ă���. ��Ⱥ������һ���Ҫ������. �ڃ�ͯ���ڣ��҂��W����΅^��؈�����ֲ���������M�����R�����. ͨ�^�ԄӾ���҂������R�e������g�е��ܼ��^���ϡ��^�Ķ��l�F���w�ֲ�ģʽ�͔�������֮�g��Ȥ���P. ������яV���������S�������I�����Ј��о���ģʽ�R�e�����������͈D��̎��. �ژI���У���Ⱥ���Ԏ����I�N�ˆT�l�F��͑��M�еIJ�ͬ�M��������ُ�Iģʽ�������͑��M. ������W�У������������ƌ�����ֲ���˜ʣ����������ƹ��ܵĻ����M�з���������˽�NȺ�ăȲ��Y��. ��Ⱥ߀���Ԏ����ڵ����^�y���R�e���Ƶ�����ʹ�Å^����������ͣ��rֵ�͵���λ�ô_�������е�ס��e��������܇���U���F���γ����˴_�����ߵ�ƽ�����r�ɱ�. ��Ҳ�������ڎ��������Ϣ�l�F��Web�ϵ��ęn���. ��ijЩ���ó����У����Ҳ�Q�锵���ֶΣ�����������������͔������������Ԍ���֞���. ���Ҳ���������xȺֵ�z�y. �xȺֵ�z�y�đ��ð����z�y���p�ͱOҕ����̄��еĻ��. ���磬�����еĮ�����r������dz����F���l��ُ�I�����������p��ӵĘ�־. ���锵���ھ��ܣ���������������������ߣ��������˽┵���ֲ����^��ÿ���������������ע���ض��ľ�����M���Mһ������. ���ߣ����������������㷨���A̎�����E����������������Ӽ��x��ͷ��Ȼ���z�y���ľ���x���Č��Ի������M�в���. K��ֵ��ʹ����V���ľ����. ������������k-Medoid���Ӿ��DBSCAN. �������EM��Ҳ�����ھ�����Ľ�Q����. ��������S���I���Б��ã����电���ھ��Ј��о����xȺֵ�z�y. ���⣬���S���gҲ��һ�N����ھ�����ğo�O���W������������ʹ��������ɷַ�����PCA���������Єe������Isomap. [������Դ: Han J .������M.�Ὠ��2011��. �����ھ�: ����ͼ��g. Ħ����������. ] �P�ھ�����������о��_ʼ��60��ǰ-K-means�㷨�ij��F��ԓ�㷨��Steinhaus��1955���״������Ȼ��Stuart Lloyd��1957�������K-means����㷨. ���]ϵ�y��ʹ�õļ��g. �Ñ����Է֞鲻ͬ�ĽM�ԫ@����ᘌ��ԵĽ��h. ��ˣ�������֞鑪���A��. 1978�꣬David Harrison��Daniel L Rubinfeldʹ��K-means����㷨�о����خa�Ј�����. ����ʹ�÷��خa�Ј�����������ُ�I�坍�՚����Ը. 1987�꣬Kaufman��Rousseeuw����ˇ��@Medoids����M�зօ^�ķ�����ԓ�������҂��F����Ϥ���S�����㷨�Ļ��A. 1992�꣬Vladimir Batagelj��Anu?kaFerligoj��Patrick Doreian�_�l��һ�N���M���ض�λ�㷨��һ�N���M�ľۼ��Ӵ��㷨. ��1996�꣬Martin Ester��Hans-Peter Kriegel��J?rgSander��Xuxiaowei�����ʹ����/ DBSCAN�Ļ����ܶȵđ��ó�����g���. ���㷨�����ܶ�: �o�����g�е�һ�M�c��ԓ�㷨���Ԍ��������c�w��һ�M�������S�������c���c��������ӛ��λ�ڵ��ܶȅ^���е��cDBSCAN����õľ�����㷨֮һ��Ҳ��������õĿƌW����֮һ���@��������a�������h��Ӱ�. 2014���߾S�������ԓ�㷨�ڔ����ھ���hKDD�ϱ����衰�r�g�yԇ������ԓ��헱���������Փ�͌��`ˮƽ��һֱ�ܵ��Pע��ijЩ�㷨. ͬ���߾S��������Q����ʹ�ÌӴνY����ƽ������p�ٺ;��BIRCH������. BIRCH��ʹ�ÌӴνY���M��ƽ��ĵ����s���;����һ�N�o�O���Ĕ����ھ��㷨�����ڌ��e��Ĕ��������зӾ��. BIRCH��һ�����c�ǣ��������f���غ̈́ӑB�ؾۺ�ݔ��Ķ�S�y�������c���Ա��o�����YԴ�����ȴ�͕r�g���ƣ���������|����Ⱥ��. �ڴ������r�£�BIRCHֻ��Ҫ����һ��. ���İl�����QBIRCH�ǡ��I��������ĵ�һ����Ч̎���������������c���ǻ���ģʽ��һ���֣��ľ���㷨��������ģ�����ܷ��������DBSCAN. ԓ�㷨��2006���Ƴ����s�@SIGMOD10��yԇ��.
�P�ھ�������о��ѽ��ஔ���죬Ŀǰ�����ھ���㷨�Ĺ��I������. ���磬��2005���ԁ���Netflixʹ��DBSCAN�����Ү����ٶȱ��������������ö�Į���������. 2011�꣬Roman Filipovych�����W�������˾������yԇ�Ľ�����r�����u�����������ڰl�F���XMR�D�����}�ľ����������. ʹ��IEEE�����r���҂��l�F��1500�f���c��������P�ĽY�������ǣ�������H�ܵ��ؚw�����Pע��һ�룬���ԓģ�Ϳ��ܱȹ����ĸ�֪���x߀С. ��� �¼� ���PՓ��/�����īI 1955 Steinhaus�����K-means�㷨��ԭ�� Steinhaus��H.��1956��. ���ӈF�w�x��. Bull.acad.polon.sci.cl.iii��801-804.
1957 Stuart Lloyd�����_�l��K-means�㷨��Ҳ�Q��Lloyd�㷨�� �ڰ��£�Lloyd��S.P.����1982��. PCM�е���С����������IEEE��Ϣ��Փ�W��28��2��: 129�C137. 1978 Harrison D.��Rubinfeld D.L.��K-means����㷨�о����خa�Ј����� Harrison��D .�� Rubinfeld��D.L.��1978�����혷���x��ס���r��͌��坍�՚�������h�������c������. 5��1��: 81-102. 1987 Kaufman��Rousseeuw����ˇ��@̴���ķօ^�����@̴���ķօ^��
Kaufman��L .�� Rousseeuw��P .�� ��1987��. ����̴��M�о��. ����L1���������P�����ĽyӋ��������. 405-416�. 1992 Vladimir Batagelj��Anu?kaFerligoj��Patrick Doreian�_�l��һ�N���M���ض�λ�㷨��һ�N���M�ľۼ��Ӵ��㷨 Batagelj��V .; A. Ferligoj�� Doreian��P.��1992�꣩�����Y�����ȵ�ֱ�Ӻ��g�ӷ����������罻�W�j��. 14��1-2��: 63-90. 1996 Martin Ester��Hans-Peter Kriegel��J?rgSander��Xuxiaowei����˻����ܶȵđ�����/ DBSCAN�đ��ó�����g��� Ester��M.; Kriegel��H.-P .;ɣ�£�J. Xu��X.��1996��. һ�N�����ܶȵ��㷨�������ڎ������Ĵ��Ϳ��g�аl�F���. �ڶ���֪�R�l�F�͔����ھ���H���hՓ�ļ���KDD-96��. 1996
�Q����ʹ�ÌӴ�/ BIRCH�����ľ�������s���;�� Zhang��T .;���R����ϣ�ϣ�Ramakrishnan��R.�� Livny��M. ��1996��. BIRCH: һ�N���ڴ��͵���Ч���������. 1996��ACM SIGMOD���H�������������96������ĕ��h�. pp. 103�C114. 2011 �_�R���M�����S�棨Roman Filipovych���ȌW�����þ�������yԇ�Ľ�����r Filipovych��R .; Resnick��S.M .�� Davatzikos��C.��2011�꣩. Ӱ���İ�O�������. NeuroImage. 54��3��: 2185-2197. �����һ����M������о��I��. �����Ǿ�������R��һЩ��������: �ɔUչ��: �S�����㷨�m���ڰ������ڎװق����������С�͔�����. ���ǣ����Ϳ��ܰ��������f������. ������������ܵ�Ҏģ������K��ֵ����Ӱ푣��Еr�����Ǻܿɿ�. �ض����͔������Ęӱ�����ܕ����½Y����ƫ�����҂���Ҫ�߶ȿɔUչ�ľ���㷨. ̎����ͬ��͵Č��Ե�����: �S���㷨ּ�ڌ������g���ģ����֣������M�о��. ���ǣ����ó��������Ҫͬ�rȺ��������͵Ĕ�����������M�ƣ�����˷Q���������������@Щ������͵Ļ��. ������ij�����x��������㷨���l�F���������Π�ľ��: �S�����㷨���ǻ��ښW����þ��x������Manhattan���x�������_�����. �����@�N���x�������㷨�������ҵ���С���ܶ����Ƶ����δ�. ���ǣ��ؿ������κ��Π�. �_�l���ԙz�y�����Π�Ĵص��㷨�dz���Ҫ. ����ij�����ֵ���_��ݔ�녢�����I��֪�R�����Ҫ��: �S�����㷨Ҫ���Ñ��ھ������ݔ��ijЩ����������������ľ����. ��Y�����܌�ݔ�녢���dz����У���ȡ�Q�ڷ����ˆT�������_���x���Ҿ�����Ľ�Q�������ܲ���Ψһ��. ���ǣ��@Щ�������ڌ��H��r��ͨ�����y�_���������nj��ڰ����߾S����Ĕ�����. �@���H�o�Ñ�ؓ��������ʹȺ�����|���y�Կ���. ���⣬��DBSCAN�У�������������ܶȲ�һ�£��t���y�_���ŵ��x��. ̎��������������: ������F�������������ֵ��Gʧ��δ֪���e�`�Ĕ���. һЩ����㷨���@Щ�������У������܌����|���^��ľ�Y��. ������͌�ݔ��ӛ䛵��������: һЩ����㷨�o�����²���Ĕ����������£��ϲ����F�еľ�Y����. �෴����횏��^�_ʼ�_��һ���µľ��. ��������㷨��ݔ�딵�����������. �Q��Ԓ�f���o��һ�M���������@�N�㷨���Ը���ݔ�댦��ı�ʾ������@��ͬ�ľ��. �_�l��������㷨�͌�ݔ��������е��㷨�dz���Ҫ. �߾S��: �����������S�Ȼ����. �S�����㷨���L̎���;S�������H�漰���S�����S. ���۷dz����L�Д���_�����S�ȵľ���|��. �ڸ߾S���g�в��Ҕ��������Ⱥ���dz����������ԣ������ǿ��]���@Щ��������ϡ���Ҹ߶�ƫб. ���ڼs����Ⱥ��: ���H���ó��������Ҫ�ڸ��N�s������Ⱥ��. ���O���Ĺ������ڳ������x��o�����������Ԅ��y�ЙC��ATM����λ��. Ҫ�����@�ӵěQ���������Կ��]���к�����·�W�ȼs���l�����Լ�ÿ����Ⱥ�п͑�����ͺ͔���������ͥ�M�зֽM. �ҵ��M��ָ���s���������������ܵľ�Y���dz�����������. �ɽ���ԺͿ�����: �Ñ�������Y���ǿɽ�ጵģ�������ĺͿ��õ�. �Q��Ԓ�f��������Ҫ����������ض����Z�x��ጺ͑���. �о�����Ŀ�����Ӱ푼�Ⱥ���ܺͷ������x�����Ҫ. ���⣬����Փ���v�������ʼ�K���O���ڷֽM�������@�N���O���������Ļ��e�`��. �ڌ����đ����У����������������һ�������g. �ƺ�߀����ʹ�á���Ⱥ�����g��p���e�`��ʹ��������ӿɿ��ͷ������������ڸ����ИI�Б���. ����: �����£���Ī˹
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y �֙Cվ �P�ڱ�վ