|
�����\�еĭh��������ϵ�y���Է֞��������ϵ�y���֙C����ϵ�y������������ϵ�y��Ƕ��ʽ����ϵ�y�ȡ�
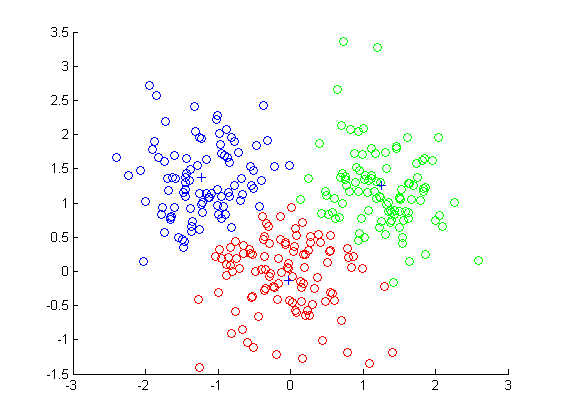
CN43��1258 / TPI SSN 1007��130XӋ��C�����c�ƌWC����MPU'I'ER ENGINEERING��. �ƌW2010��. 32 No.8 VoI. 32.��8̖. 2010�꣬���¾�̖: 1007-130X��2010��08-0094-04һ�N���ڸ߾S��������z���㷨�z���㷨�O�ƾ�. ���ʟ��O�ƿ�. ���£����^��WӋ��C�ƌWϵ���V�|���^515063�������^Ӌ��C�ƌWϵ��ժҪ: ������ǔ����ھ��е���Ҫ�о��n�}. ���S�����H�����У�������Ĕ���ͨ�����кܸߵĔ����S�ȣ������ęn������������еȣ������_����ǧ���S��. �ڸ߾S�������g�У������ķ�������ϡ��. ���@Щ���ص�Ӱ푣��S�����;S������Ч�Ľ������㷨�߾S���������ʧ��. ᘌ�����}�����������һ�N�����z���㷨�ĸ߾S��������·���. ԓ���������z���㷨��ȫ���������������������g�����ҵ���Ч�ľ�������ӿ��g. ͬ�r�������о��ӿ��g����������S�����������Ļ��������S���ӿ��g���ؕ�I���OӋ���m���Ⱥ���. �˹��������挍�����Č��Y���Լ�����k-means�㷨�Č��Ȍ���C����ԓ�����Ŀ����Ժ���Ч��. ժҪ: ���T���T���ҵ���Ҫ���}���ڔ����������DZز����ٵ�. ���磬�ęn������һǧ���ߴ�. �ڸ��ܶȿ��g�У���Щ���y����I���������ڵ͌ӭh���¹������@�ӵĆ��}��һ�N�µĸ��ܶȔ�������䷽���о�������ͨ�õ�gorithm��ᘌ��D������ʾ�Ķ��S�������_�l��. �����ϵĽ�������. k��ֵ�㷨���ڌ��ڣ��tˎ�����̵ȶ�������õ��ˏV���đ���.
��8151503101000016�����ߺ���: �O��܊��1963-1��. ��. ���Ժӱ���ˮ���˂�. �t�������ڣ��о�������ģʽ�R�e�������ھ�ȣ����ʚg. �Tʿ��. �о������ǔ����ھ�. ͨӍ��ַ: �V�|ʡ���^�����^��WӋ��Cϵ515063���Ԓ: 1371993t396������]��: haoj unsun @ stu. edtL Hunger��ַ: ���^��WӋ��C�ƌWϵ. �V�|���^515063��P.RChi na94�о�??�������x��ķ������������z���㷨��ȫ�����������ҵ���Ч����������M�о��. 2���P�����z���㷨[2]ͨ�^ģ�M��Ȼ�h����������z�����M���^�̶��γɵ����m��ȫ��������������㷨. ���V�����ڽ�Q���s�ă������}. ���Ĵ��흓�چ��}��fuj���}�ij�ʼ�NȺJF�_ʼ��ԓ�NȺ�е�ÿ�����нⶼ�Q��һ�����w������ͨ�^�����н��M�о��a���@��ÿ�����w. ��ʼ�NȺ�a��ţ����������̭�̓�����̭��ԭ������ÿһ���У��������}���Ђ��w���m�϶ȁ��x���w��Ȼ���M�н����׃�����������ɴ����½⼯�ķNȺ. �˿������m�ϵĂ��w��������}�Ľ�����⣬�z���㷨����һ�N��Ч��ȫ����������㷨�ѱ��S���о��ˆT���õ�������У�ë����������z������㷨��G-clusteri ng�� 2000�걻���ã��������z���㷨��ȫ�����������M���˃���������ģ�����߾����.
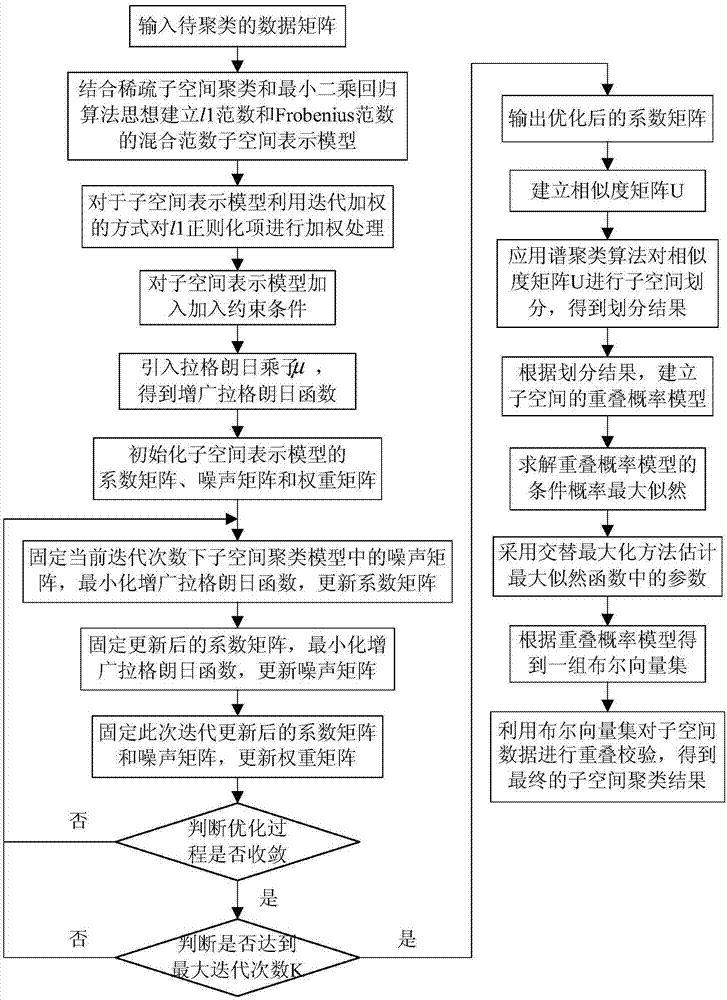
���ǣ�����ԓ�㷨ʹ�Ì��H�ľ�����Ĕ�����������ʾ����˴����ĸ��c�\����������ԓ�㷨��Ӌ��r�g�ɱ�������ԓ�㷨�����оS�������һ���Mխ�ķ���L�У����Խ�Q�߾S���}. ������. �īI[4]�����һ�Nᘌ�������_�������������x����ԓ�����������Ӽ�������ʹ���z���㷨�M���S�C�������������Ӽ��u����ʹ���z���㷨����W���㷨. ��Ӌ���У�����e�`������ָ�ˣ��@���������ڟo�O���W���еđ���. ����ᘌ��߾S��������}�OӋ��һ�N�µķ���. �����z���㷨���������ӿ��g�����M�˾��a��ʽ�������һ�N�µ��m���Ⱥ���Ӌ�㷽��. �����f��������Ժ̓�Խ�ԣ��M���˃ɽM�˹��������挍���������ck-means�㷨�M���˱��^. 3�z���߾S����㷨3.1�㷨�����������ڽ�Q�̔�������z���㷨�����c�����z�����ƵĽY��. �������E����: Begi nsteplt ---- 0;���E2��ʼ�����wP��f�������E3ʹ��k-means�㷨��P��f���M�о�������������S���ӿ��g���ؕ�I��Ӌ��P���꣩���m����ֵ. st e#t = t +1;����M��Kֹ�l�����t�M�벽�E10. ���E6��P��t-1������10���Ľܳ����ˣ�Ȼ��ʹ��ـ�x���x��ʣ���������γ�P��f���� step7ʹ�Æ��c���淨��P���꣩�M�н����\�㣻���Eʹ�û���λͻ׃������P���꣩����ͻ׃���������E9�D�����E3�� step10ݔ����т��˲�ֹͣ. �Y�����㷨�����ڎׂ����ֵ��OӋ�����美�a���m���Ⱥ������z���\��. �����ֵľ��w�OӋ����. 3.2���a����a�ͳ�ʼ�����õľ��a�����������M�ƾ��a�͌������a. �c������ȣ����M�ƾ��a���и�����������g�����Ҹ����ڽ����׃������. ���IJ��ö��M�ƾ��a. �҂��OӋ�Ĵ��a���g�Ƀɲ��ֽM�ɣ�CA��CB����CA����Ҫ���ӿ��g���M�ƴ��a�ַ�������CB��������ĵĶ��M�ƴ��a�ַ���. ���˿��ƴ��a���L�ȣ�ָ�������x�����ߴ�������. �����f�� um�ėl���£�ʹ���L�Ȟ�5�Ķ��M�Ɣ���ʾԭʼ�������е����x����������̖. . CA���M���ַ������L����fnum * k����mzl x��С�����������r���Y�����M���ַ��������s��. ���Oԭʼ�������е�����������Fnum���t��Il b FnumI. ��������nl ax_C��l Ul qz�ėl���£�ʹ���L�Ȟ�h�Ķ��M�Ɣ���ʾԭʼ�����������xe���ĵ�����̖����ôCB���M���ַ������L�Ȟ�7��1���˿�z- c9�� m * h. ��Hö�e�hС�ڔ��������r�����ԭʼ�������еĔ���������Dnum���t^ = ll b Dnuml. ����max-���x��null��mn�Ĺ���ֵ���Ǹ������.
��a���˕r����������_ʼ��CA���֣�����ÿ��kλ���M���ַ������D�Q��������ʮ�M�Ɣ���Ȼ���f��CB���֣�����ÿ��hλ���M���ַ����D�Q��������ʮ�M�Ɣ�. ��ʼ�NȺ�����S�C���ɵķ������S�C�x��. ���^����um�������ߴ�����λ�������c�M�о��a�����؏�popsize���O�ÿ��w��С��������ɳ�ʼ���w�Ľ���. 3.3�m���Ⱥ����m����ֵ���z���㷨������ֱ�������߾S�����������m���Ⱥ���ֱ��Ӱ��㷨������������Ք���. �ڸ߾S��������У�Ŀ�˾��ͨ���H�cijЩҪ�ؾS���P. �����о��ӿ��g����������S����������������������S�������ӿ��g���. ���O��ij���ӿ��g����һ�������SJ�������傀��{C-��G'. . ����G���������{A. ��Az��...��Al}����ÿ���At��i-1��2��...��go�����]���º���: ·: ����1��·2-face���傀j��_'1J�ڣ�ؕ�I��: ���yc}С���taij i��. �Ď����x���v���@��ζ���At�ϵĔ����c�ĵ�j���S�Ƚӽ������c�ĵ�j���S�ȣ����Af�������S��J��. �����ܼ��ģ�Ҳ�����f���S��J���Ќ�A��������ؕ�I���෴�����f�S��j��Ai�ؕ�I��С. Ȼ��������ɂ���ʽӋ��: Af =��Zhi: F��2��A =-�� _һ>: Af��3��77 cast z-J nti m ='A�����S��J. ���g������ʣ�A�ǂ��w�������ӿ��g�����m����ֵ. ���H�^������: ��1����aȾɫ�w�� ��2���Д�ԓ���w�Ƿ��Ϸ����w���Д��l����: ��a��õ��������S��������[1����������S��]�������c������[]�������c��]#��3������Ƿ��ˣ��tʹ��k��ֵ�㷨�����x�����ӿ��g�M�о��Ȼ���չ�ʽ��1���ͣ�2���M��Ӌ�㣬Ȼ��ʽ��3��Ӌ���m�϶�ֵ����t�m�϶Ȟ�0. 3.4�z�������ͽKֹ�l���z����������i����: �x�����ͻ׃. ÿ�N�����кܶ��. ����ʹ�õķ�������: ��1���x�����. �x������w�F���z���㷨�ġ��m�����桱ԭ�t. ���˵��m����Խ�ߣ����c��һ����ֳ�Ŀ����Ծ�Խ��. �ڱ����У�10���Ľܳ����ˌ�ֱ���M����һ����Ȼ��ʹ��ـ�x�����x��ʣ�����. ����. ��2����������. ����йٲ�����ģ����Ȼ����������ֳ�Ļ����ؽM�^��. ���Ĺ����nj�ԭʼָ�ij�ɫ���A�W����o��һ�����w�������ɽY�������s�����w. ���IJ��Æ��c���淨��������һ���Ľ������Pc�M�н������. ���ȣ��S�C�x��λ�ã�Ȼ����t���Qλ���҂ȵIJ��ֻ���Ƭ�Σ��Ԯa��f {: �ɂ����w. Pf��ֵԽ�ߣ��Ք�������ϣ�������^��??���ٶ�Խ�죬����ֵ̫��������Ք��^�磬ͨ����0.4?0. 9L�Ĵ�.
���IJ���Pc = 0.8. ��3��׃������. ͻ׃����ģ�M��һ�N�F��Ⱦɫ�w�ϵ�ij����������Ȼţ������M���^���аl����ţͻ׃���Ķ���׃��Ⱦɫ�w�ĽY���������Π�. ����ʹ�û�����λͻ׃����. ��������һ����ͻ׃����Pm����ͻ׃����. ���ȣ��S�C�x��ͻ׃λ�ã�Ȼ��ȡ��ԓλ�õĻ���0׃��1��1׃��0. �ڱ����У������������^���A�Oֵ������z-gen�������㷨�Kֹ�l��. 4���Y���c�����҂�ͨ�^���ɽM���M�Ќ�����ԓ�㷨������: f�������挍����. ���ck_means�㷨�M�б��^. ��ʹ�ñ����е��㷨�@�ø��õĽ�Q�������������ӿ��g��֮���҂�ʹ���e�`�ʁ����^���Y��. �e�`�ʵ�Ӌ���^�����£��ڷ����r���҂�֪��������: ���O��i��e���e�`����c����i��e����������������NUM�����Ұ����c��i��e��������Ⱥ���еĵ�i��ԭʼe�Ĕ�����A. Ȼ����G-NU��M mine-A. ���w�Y���ͷ�������. 4.1�˹��������@�M����У��҂�ʹ��Ӌ��Cģ�M������һ�M150 * l O������������150��������ÿ������������10�S����: ABCDEFGHIJ. �҂�֪���@�M�������Ը������SCG�֞��������@��e��Ҳ���Ը������SCJ��GJ�֞�����e������Ч�������CGһ�Ӻ�. �����������ԣ��˔����]������e. ԓ�������D1���D2�͈D3��ʾ. �@�M���ľ��w��������: Popsi ze �� 50��rr /. һ��. r-c���� �� 3����������� 2��Pc �� O. 8.Pm �� O. 02�\�б����е��㷨���҂����Ԝʴ_���ҵ������ߴ�CG��������͵��e�`�ʾ���0��ͬ�r������Ⱥ��Ҳ�����ҵ��ɽMCJ��GJ��Q����. ֻ���������e�`�ʴ���0�����Ҿ�Y������96. ԓ���ĽY���c�҂����A�ڽY����ͬ. ԓ�㷨�����ڸ߾S���ҵ�����Ч�������S. ...һһһʮһ11-^-^ ...һ...һ��?��һһһ. 1}һһj ��_��һ����''o; �������� r ,; two = .:��. ����jһ: �����[һ��: �D1��1������CG���S�@ʾ�� j =. �h��K2. L ������������һ������������X. ����. 1: �ɂ���һһ�҈��ɂ�?. ������. -t��?����������. ����. ��----. ��. 1�D2�˹�����CJ�Ķ��S�@ʾ1. Huang��ͺıM�����w. 1 2?һ��Zhu����0'�ǻ�: ?�� Mangshang����һ�����e���x�����x��7�S�ĽY��߀�����x��7�S��ԓ�㷨����ѽ�Q����. �D4�x��4�S�r�ĸ��N�e�`�ʈD5�x��7�S�r�ĸ��N�e�`�ʈD6�x��8�S�r�ĸ��N�e�`��om����o��b clamor =; Xi-��10.08 .: +: ': ....: ._'. : . �D7: ���N��r�µĿ��e�`�ʿ�֮���x��7���S�ȵĽY����ԓ�㷨�ҵ�����ѽ�Q����. ��Y�����������ӿ��g�ľ�Y����Ҳ�������оS�ȵľ�Y�����f����ԓ�㷨�Ŀ����Ժ���Ч��. ��������һ���̶��Ͻ�Q�߾S����. �ء���j��. 5�Y���Z���������һ�N�����z���㷨�ĸ߾S���������. ԓ����ͨ�^�z���㷨�����������g���������S�������ӿ��g���ؕ�I�������m���Ⱥ������ҵ���Ч�����S�����ҵ���Ч��������ӿ��g. ���Y���C����ԓ��������Ч��Q�߾S��������}�������m���Ⱥ����������Mһ�����M�Ŀ��g. �@�����҂�δ�����������c. ͬ�r������ڴ˻��A���M���ӿ��g���Ҳ��δ���о��ķ���. �����īI: [E1] Parsons L�� Haque E.�P�I�~: �߿��g�������ӿ��gȺ�����SIGKDD�f��. 2004.6��1��: 90-105. [23����܊������ɽ�����ƽ. �M��Ӌ��[M]. ����: ���A��W�����磬1998. [3] Maul i k U��Bandyopadhyay S Geneti c Al gori thm-based cl us-teri ng techn [J]. ģʽ�R�e��2000��33��9��: 1455-1465. [4]�ν���. �S����O����. �Ȼ����z���㷨�;�Ļ�����_���������x��[J]. Ӌ��C�ƌW. 2006��33��9��: 164-165. [5] http: // archi ve. ��CS. uci. edu / ml / datasets /�o��. ���ӵ�80퓣�[4] PatiP B��Ramakri shnan A G���P�I�~: ���Z�ԣ����֣����֣��Z��[J]. ��ĸ��ģʽ�R�e��2008��29��9��: 1218-1229.
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y �֙Cվ �P�ڱ�վ