|
�����\�еĭh��������ϵ�y���Է֞��������ϵ�y���֙C����ϵ�y������������ϵ�y��Ƕ��ʽ����ϵ�y�ȡ�
Longyuan Journal���ھW�j��HDFS�ֲ�ʽ�惦���Է���: ���ڵҽ����Դ: ������Ӌ��C�c���á� 2016��01��ժҪ: �������c��BHDFS�C�ܸ�֪������HDFS�ֲ��ĸ����惦���Է�����ʹ惦. �����惦���Ժ͙C�ܸ�֪��Ҫʹ��Datanode���c�γɵĘ��W�j�ؓ���@ȡNamenode���c���Ķ��_�������惦��λ��. �@�N�����_���˔����ĘO�����e������ͬ�r߀���]�˱��ؔ���. ������˼�Ⱥ�W�j�Д�����ݔ��Ч��. ���ڴˣ������һ�����O. ϣ��ͨ�^�����ھ��惦���ԣ�����Datanode�������c�Č��r��B��Ϣ�����F�����K�����Ķ���惦���M�����F�����ӵ��΄շ���. ����oÿ��Datanode�������c. �����m���΄Ձ팍�Fؓ�dƽ�Ⲣ����YԴ������. �P�I��: HDFS���ֲ�ʽ�惦�����ƴ惦���ԣ������ӵ����ĈD���^���̖: TP391.41�ęn���R̖: A����̖: 2095-2163��2015��05-ժҪ: �������c��BReplicationTargetChooser��RackAwareness�IJ��ԁ�����HDFS�ֲ�ʽ�惦. ���ˌ��FReplicationTargetChooser��Rack-Awareness�IJ��ԣ�HDFS�γ���Datanode�ľW�j�ؓ�䣬��Ҫ��Namenode���c�_������λ�ã��Ķ��_���ڿ��]������ͬ�r���ИO�ߵĔ������e�������أ������Ⱥ���W�j�Д�����ݔ��Ч��. �ڴ˻��A�ϣ����������һ���뷨��ϣ���Mһ���˽�ReplicationTargetChooser�IJ��ԣ����ڌ��r�Ġ�B��ϢDatanode���c�팍�F�����K�Ķ��������ӵ��΄����·���oDatanode��ÿ�����c������m���ڌ��Fؓ�dƽ��Ч��������YԴ�����ʵ��΄�. �P�I��: HDFS���ֲ�ʽ�惦�����Ʋ��ԣ�������0������21���o������ѽ�̎����Ϣ�r������ÿ�춼�ڮa����������. ��δ惦�������@Щ���������ѳɞ�IT�����ߣ��������������������˂��Pע�ğ��c�о����}.
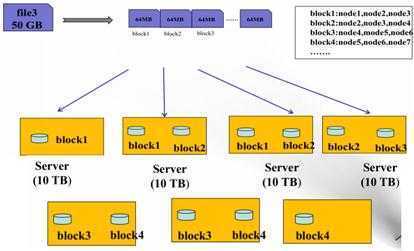
���ǣ��ʹ惦���g���惦�ٶȻ��惦��ȫ�Զ��ԣ����y�ļ�ϵ�y�o���M�㮔ǰ��̎��Ҫ��[1]. ֱ�������Hadoop�ij��F���Ş�ԓ���}�@����ͻ���ԵĽ�Q����. Hadoop�����һ�N�F����Ч�Ľ�Q���������ڴ惦��̎����������. ���hdfs�ֲ�ʽ�惦��Hadoop���ܵ�Google��Yahoo��Amazon��֪��IT��˾����A. �T���vӍ������ٶȣ��A���һЩ���ȹ�˾�ѽ���Hadoopҕ����I̎�����������Ľ�Q����[2]. HDFS�ֲ�ʽ�ļ�ϵ�y��Hadoop�ĺ��ĽM����Ҳ�ǽ�Q�����������惦�����õ���Ҫ���g�ֶ�. ��ˣ������˽�HDFS�ֲ�ʽ�ļ�ϵ�y�Ĵ惦���Ԍ�HDFS�ֲ�ʽ�ļ�ϵ�y��δ�푪�ú��M������Ҫ���x. 1���ƙC��HDFS��ÿ���ļ��Ĕ����惦�ډK�У�ÿ�������K�惦��������. �ض������ĸ���������hdfs-site.xml [3]��dfs.replication����������. �����Ĕ����K�����ֲ��ڲ�ͬ�ęC�����c��. �@�N�����K�惦+���Ʋ�����HDFS�_���ɿ��Ժ����ܵ��P�I����Ҫ�����: ��1�����ļ��惦�ډK��֮�����������K�����M���xȡ. ������ļ��S�C�xȡ��Ч�ʺͲ��l�xȡ��Ч�ʣ� ��2���������K�Ķ����������浽��ͬ�ęC�����c�ϣ��ڌ��F�ɿ��Ե�ͬ�r��߀�����ͬ�r�xȡͬһ�����K��Ч�ʣ� ��3��������ֹ�cMapReduce�е��΄շֶε�˼��߶�һ��.
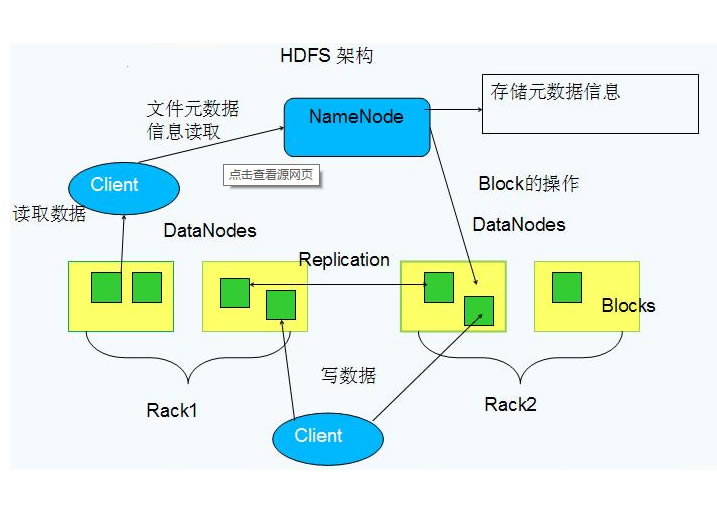
���@������惦�����ٴγɞ�HDFS���F�߿ɿ��Ժ����ܵ��P�I�͛Q�������}. 2�C�ܸ�֪HDFSʹ�÷Q��C�ܸ�֪�IJ��ԁ���ߔ����ɿ��ԣ������Ժ;W�j����������. ͨ�^�C���R�e�^�̣�Namenode���Դ_��ÿ��Datanode���ٵęC��ID. ���H�ϣ�Namenode�������P��ip��ַ�Ԙ��W�j�ؓ�惦��ע�Ե�Datanode���c��Ȼ��Namenode�{��ReplicationTargetChooser��ÿ�������K�����x���m���Ĵ惦���c. ����hdfs�ֲ�ʽ�惦��Hadoop���C�ܵĸ�֪�������m���ģ�Ҳ�����f��Hadoop��Ⱥ���ԅ^���Ă��ęC�����Ă��C�ܶ�����ϵ�y���X�ģ�������ҪHadoop�������˞��֪ͨHadoop�Ă��C�������Ă��C��
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y �֙Cվ �P�ڱ�վ