|
����(j��)�\(y��n)�еĭh(hu��n)��������ϵ�y(t��ng)���Է֞��������ϵ�y(t��ng)���֙C(j��)����ϵ�y(t��ng)������(w��)������ϵ�y(t��ng)��Ƕ��ʽ����ϵ�y(t��ng)�ȡ�
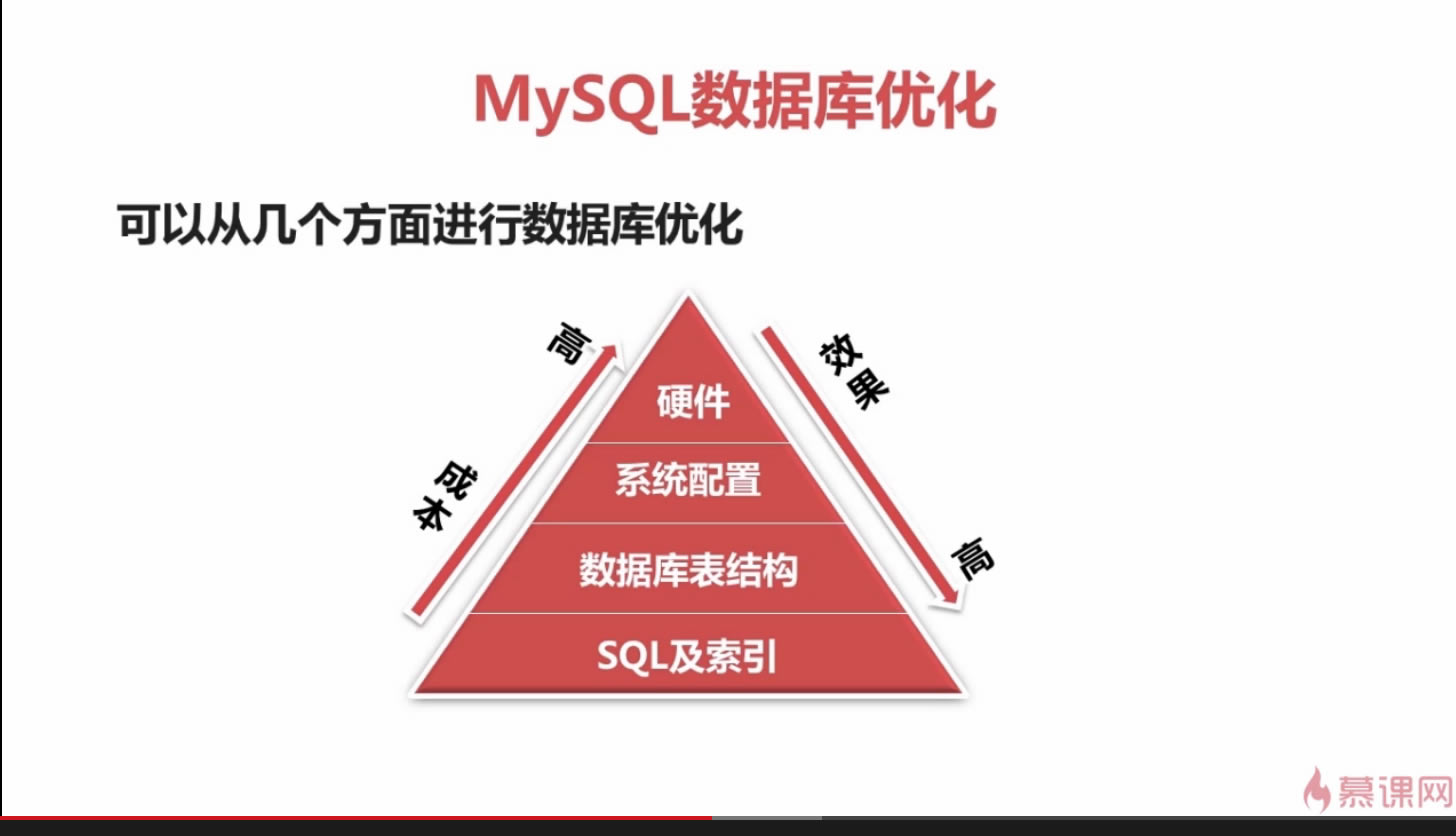
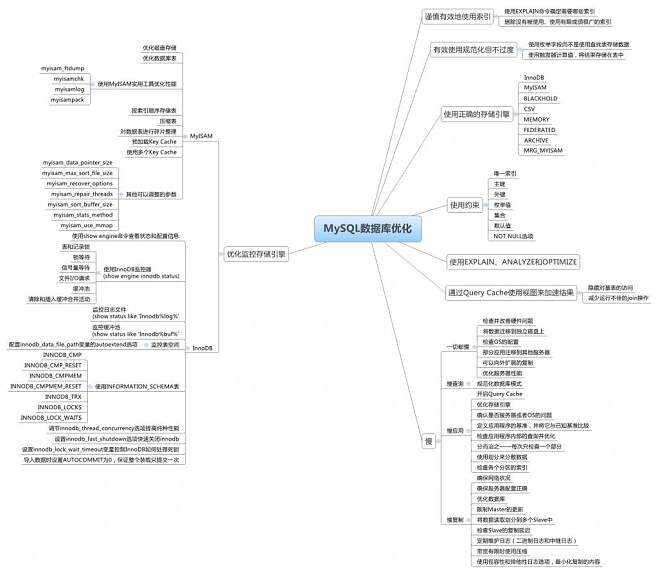
���S������ԃ�(y��u)��. �����������x��ԇ���}�������Y(ji��)��һЩ��(y��u)���ķ���. ��(y��u)���ķ��� 1. �x�����m�õ��ֶΌ��� MySQL���Ժܺõ�֧��(du��)������(sh��)��(j��)���L��������ͨ�����f���еı�ԽС����(du��)���(zh��)�еIJ�ԃԽ��. ��ˣ��ڄ�(chu��ng)����r(sh��)�����˫@�ø��õ��������Ӄ�(y��u)�����҂����Ԍ������ֶεČ����O(sh��)�õñM����С. ���磬�ڶ��x�]�����a�ֶΕr(sh��)����������O(sh��)�Þ�CHAR��255�����t�@Ȼ��(hu��)�����Ӳ���Ҫ�Ŀ��g. ��ʹʹ��VARCHARҲ�Ƕ���ģ���?y��n)�CHAR��6�����Ժܺõ�����΄�(w��). ͬ�ӣ�������ܣ��҂���(y��ng)ԓʹ��MEDIUMINT������BIGIN�����x����(sh��)�ֶ�. ��һ�N���Ч�ʵķ������ڿ��ܵ���r���ֶ��O(sh��)�Þ�NOT NULL���Ա㌢���ڈ�(zh��)�в�ԃ�r(sh��)����Ҫ���^NULLֵ. ��(du��)��ijЩ�ı��ֶΣ����硰 province���� gender�����҂����Ԍ��������x��ENUM���. ��?y��n)���MySQL�У�ENUM��ͱ�ҕ�锵(sh��)��?j��n)?sh��)��(j��)�����Ҕ�(sh��)��?j��n)?sh��)��(j��)��̎�����ı���Ϳ�ö�. �@�ӣ��҂�������ߵ�����. 2. ʹ��JOIN�����Ӳ�ԃ MySQL��4.1�_ʼ��֧��SQL�Ӳ�ԃ. �˼��g(sh��)����ʹ��SELECT�Z�䄓(chu��ng)�����в�ԃ�Y(ji��)����Ȼ��ԓ�Y(ji��)��������һ��(g��)��ԃ�е��^�V�l��. ���磬����҂�Ҫ?ji��ng)h�����͑�������Ϣ�����Л]���κ�ӆ�εĿ͑����t����ʹ���Ӳ�ԃ�����ȏġ��N����Ϣ�����Ы@ȡ�l(f��)����ӆ�ε����п͑�ID��Ȼ�Y(ji��)�����f�o��Ҫ��ԃ��������ʾ: DELETEFROMcustomerinfo WHERECustomerIDNOTin��SELECTCustomerIDFROMsalesinfo�� ʹ���Ӳ�ԃ��������S��SQL�������@Щ������߉����Ҫһ����ɶ���(g��)���E. ͬ�r(sh��)����߀���Ա�����(w��)����i�����������ھ���. ���ǣ���ijЩ��r�£��Ӳ�ԃ�����ɸ���Ч��(li��n)�ӣ�JOIN������. ���磬���O(sh��)�҂�Ҫ�z�����Л]��ӆ��ӛ䛵��Ñ����t����ʹ�����²�ԃ�����:
SELECT * FROMcustomerinfo WHERECustomerIDNOTin��SELECTCustomerIDFROMsalesinfo�� ���ʹ��JOIN��ɴ˲�ԃ���t�ٶȌ�����. �e����salesinfo���е�CustomerID���������r(sh��)�����ܕ�(hu��)����. ��ԃ?n��i)��? SELECT * FROMcustomerinfo LEFTJOINsalesinfoONcustomerinfo.CustomerID = salesinfo.CustomerID WHEREsalesinfo.CustomerIDISNULL ���루JOIN��. ֮���Ը���Ч������?y��n)�MySQL����Ҫ�ڃ�(n��i)���Є�(chu��ng)���R�r(sh��)��������ɴ�߉�ɲ���ԃ. 3��ʹ��(li��n)�ϣ�UNION�������ք�(d��ng)��(chu��ng)�����R�r(sh��)�� MySQL�汾4.0���֧��(li��n)�ϲ�ԃ��ԓ(li��n)�ϲ�ԃ���Ԍ���Ҫ�R�r(sh��)���ăɂ�(g��)�����(g��)�x���ԃ�M�Ϟ�һ��(g��)��ԃ. �ڿ͑��˵IJ�ԃ��(hu��)Ԓ�Y(ji��)���r(sh��)���R�r(sh��)�팢���Ԅ�(d��ng)�h�����Դ_��������Ч. ��(d��ng)ʹ��union��(chu��ng)����ԃ�r(sh��)���҂�ֻ��Ҫʹ��UNION�����P(gu��n)�I�ց��B�Ӷ���(g��)select�Z��. ��(y��ng)ԓע����ǣ������x���Z���е��ֶΔ�(sh��)�����ͬ. �����ʾ����ʾ��ʹ��UNION�IJ�ԃ. SELECTName��PhoneFROMclientUNION SELECTName��BirthDateFROMauthorUNION SELECTName��SupplierFROMproduct
4. ��(w��) �M���҂�����ʹ���Ӳ�ԃ��JOIN��UNION��(chu��ng)�����N��ԃ�����������в�����ֻ��ʹ��һ��(g��)��ׂ�(g��)SQL�Z��. ͨ�����б�Ҫʹ��һϵ���Z������ij�N����. �������@�N��r�£���(d��ng)�Z��K�е�ij��(g��)�Z���\(y��n)�в����_�r(sh��)������(g��)�Z��K�IJ�����׃�ò��_��. ����һ�£��������ͬ�r(sh��)��ɂ�(g��)���P(gu��n)�ı��в���ijЩ��(sh��)��(j��)���t���ܕ�(hu��)���F(xi��n)������r: �ɹ����µ�һ��(g��)����ͻȻ���F(xi��n)������r���Ķ���(d��o)�µڶ���(g��)���еIJ����o������@�ӣ�������(d��o)��(sh��)��(j��)�������������Ɖ��еĔ�(sh��)��(j��). ������@�N��r������(y��ng)ԓʹ����(w��)������������: �Z��K��ÿ��(g��)�Z��IJ����ɹ���ȫ��ʧ��. �Q��Ԓ�f�����Ա����Д�(sh��)��(j��)��һ���Ժ�������. ������BEGIN�P(gu��n)�I���_�^����COMMIT�P(gu��n)�I�ֽY(ji��)β. ͬ�r(sh��)��SQL����ʧ������ôROLLBACK������Ԍ��֏�(f��)��BEGIN����(d��ng)֮ǰ�Ġ�B(t��i). BEGIN; INSERTINTOsalesinfoSETCustomerID = 14; UPDATEinventorySETQuantity = 11WHEREitem ='book'; COMMIT; ��(w��)����һ��(g��)��Ҫ�����ǣ���(d��ng)����(g��)�Ñ�ͬ�r(sh��)ʹ��ͬһ��(sh��)��(j��)Դ�r(sh��)��������ʹ���i���ķ������Ñ��ṩ��ȫ���L���������@���Դ_���Ñ��IJ�������(hu��)�������Ñ��ɔ_��Ӱ�. 5. �i�� �M����(w��)�ǾS�o(h��)�����Ե�һ�N�dz��õķ��������������������ԣ����Еr(sh��)��(hu��)Ӱ푵����ܣ��������ڴ��͑�(y��ng)�ó���ϵ�y(t��ng)��. ���ڌ��ڈ�(zh��)����(w��)���g���i������������Ñ�Ո��ֻ�ܕ��r(sh��)�ȴ�ֱ����(w��)�Y(ji��)��. ���ֻ�Ўׂ�(g��)�Ñ�ʹ��ϵ�y(t��ng)���t��(w��)��Ӱ푲���(hu��)�ɞ���}����������г�ǧ���f���Ñ�ͬ�r(sh��)�L��ϵ�y(t��ng)����������̄�(w��)�W(w��ng)վ�����t푑�(y��ng)���t��(hu��)���Ӈ�(y��n)��. ��(sh��)�H�ϣ���ijЩ��r�£��҂�����ͨ�^�i������@�ø��õ�����. �����ʾ��ʹ���i�����ķ����������һ��(g��)ʾ���е���(w��)����. LOCKTABLEinventoryWRITESELECTQuantityFROMinventoryWHEREItem ='book'; ... UPDATEinventorySETQuantity = 11WHEREItem ='book'; UNLOCKTABLES ���@��҂�ʹ��select�Z��@ȡ��ʼ��(sh��)��(j��)����ͨ�^һЩӋ(j��)�㣬ʹ��update�Z�䌢��ֵ���µ�����. ����WRITE�P(gu��n)�I�ֵ�LOCKTABLE�Z����Դ_���ڈ�(zh��)��UNLOCKTABLES����֮ǰ���]�������L����(qu��n)�ށ����룬���»�h�����. 6. ʹ�����I
�i�����ķ������ԾS�o(h��)��(sh��)��(j��)�������ԣ����Dz��ܱ��C��(sh��)��(j��)�����P(gu��n)��. Ŀǰ���҂�����ʹ�����I. ���磬���I���Դ_��ÿ��(g��)�N��ӛ䛶�ָ��һ��(g��)�F(xi��n)�п͑�. ���@����I���Ԍ�customerinfo���е�CustomerIDӳ�䵽salesinfo���е�CustomerID�����қ]����ЧCustomerID���κ�ӛ䛶�����(hu��)�����»���뵽salesinfo��. CREATETABLEcustomerinfo��CustomerIDINTNOTNULL��PRIMARYKEY��CustomerID����TYPE = INNODB; CREATETABLEsalesinfo��SalesIDINTNOTNULL��CustomerIDINTNOTNULL�� PRIMARYKEY��CustomerID��SalesID����?? FOREIGNKEY��CustomerID��REFERENCEScustomerinfo��CustomerID��ONDELETECASCADE��TYPE = INNODB; ��ʾ���У�Ոע�Ⅲ��(sh��)�� ONDELETECASCADE��. �˅���(sh��)���C��(d��ng)�h��customerinfo���еĿ͑�ӛ䛕r(sh��)��Ҳ��(hu��)�Ԅ�(d��ng)�h��salesinfo�����cԓ�͑����P(gu��n)������ӛ�. ���Ҫ��MySQL��ʹ�����I���t���ӛס�ڄ�(chu��ng)����r(sh��)��������Ͷ��x����(w��)��ȫ��InnoDB���. ԓ��Ͳ���MySQL����Ĭ�J(r��n)���. ���x�����nj�TYPE = INNODB���ӵ�CREATETABLE�Z��. ��ʾ����ʾ. 7. ʹ������ ������������ܵij��÷���. ������ʹ����(w��)���z���ض��е��ٶȱț]�������r(sh��)Ҫ��ö࣬�������ڲ�ԃ����MAX������MIN������ORDERBY����when����r�£�������߸������@. �Ǒ�(y��ng)ԓ����Щ�ֶν��������� ͨ�����f��������(y��ng)ԓ�����ڌ�����JOIN��WHERE�Д��ORDERBY������ֶ���. �M����Ҫ�����а��������؏�(f��)ֵ���ֶ�. ��(du��)��ENUM��͵��ֶΣ��ܿ��ܕ�(hu��)�д����؏�(f��)��ֵ ���磬customerinfo�еġ�ʡ�� ...�ֶ�. �ڴ���ֶ��Ͻ����������o��(j��)���£��෴����Ҳ���ܽ��͵�����. ��(chu��ng)����r(sh��)���҂�����ͬ�r(sh��)��(chu��ng)���m��(d��ng)?sh��)����������ߌ�������ʹ��ALTERTABLE��CREATEINDEX��(chu��ng)������. ���⣬MySQL�İ汾3.23.23�_ʼ֧��ȫ������������. ȫ��������MySQL�е�FULLTEXT�����������ֻ������MyISAM��ͱ�. ��(du��)�ڴ��ͣ�����(sh��)��(j��)���d��?j��ng)]��FULLTEXT�����ı��зdz��죬Ȼ��ʹ��ALTERTABLE��CREATEINDEX��(chu��ng)�������Ƿdz����. ���ǣ��������(sh��)��(j��)���d���ѽ�(j��ng)����FULLTEXT�����ı��У���(zh��)���^�̌��dz�����.
8. ��(y��u)���IJ�ԃ�Z�� �ڴ����(sh��)��r�£�ʹ������������߲�ԃ���ٶȣ��������δ���_ʹ��SQL�Z�䣬�t�������o���l(f��)�]��(y��ng)�е�����. �����Ǒ�(y��ng)ע���һЩ����. �����ȣ���ñ��^��ͬ��͵��ֶ�֮�g�IJ���. ��MySQL 3.23֮ǰ���@�����DZ�Ҫ�l��. ���磬���܌�������INT�ֶ��cBIGINT�ֶ��M(j��n)�б��^. ���ǣ���������r�£���(d��ng)CHAR����ֶκ�VARCHAR����ֶε��ֶδ�С��ͬ�r(sh��)�����Ԍ������M(j��n)�б��^. ����Σ��Lԇ��Ҫ��(du��)�����ֶ�ʹ�ú���(sh��). ���磬��(d��ng)��DATE����ֶ���ʹ��YEAE��������(sh��)�r(sh��)���������o�������\(y��n)��. ��ˣ��M�����ɂ�(g��)��ԃ���صĽY(ji��)����ͬ�������߱�ǰ��Ҫ��ö�. ���������Ӄ�(y��u)�����������ַ��ֶΕr(sh��)���Еr(sh��)��(hu��)ʹ��LIKE�P(gu��n)�I�ֺ�ͨ���. �M���@�N�����ܺ��Σ���Ҳ��(hu��)����ϵ�y(t��ng)����. ���磬���²�ԃ�����^���е�ÿ�lӛ�. SELECT * FROMbooks ��ơ� MySQL���������� ���ǣ�������Ğ����²�ԃ���Y(ji��)������ͬ�������ٶȕ�(hu��)����: SELECT * FROMbooks WHEREname> =�� MySQL�� andname <��> ���(y��ng)ע�����MySQL�ڲ�ԃ�Ј�(zh��)���Ԅ�(d��ng)����D(zhu��n)�Q����?y��n)��D(zhu��n)�Q�^��߀��ʹ����ʧЧ.
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀(g��)�ˌW(xu��)��(x��)�yԇʹ�ã�Ո?ji��n)����d��24С�r(sh��)��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ(f��)��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո���r(sh��)֪ͨ�҂�(),�҂���(hu��)���r(sh��)̎��.
Copyright © 2018-2020 �}��ϵ�y(t��ng) �֙C(j��)վ �P(gu��n)�ڱ�վ