|
����(j��)�\(y��n)�еĭh(hu��n)��������ϵ�y(t��ng)���Է֞��������ϵ�y(t��ng)���֙C(j��)����ϵ�y(t��ng)������(w��)������ϵ�y(t��ng)��Ƕ��ʽ����ϵ�y(t��ng)�ȡ�
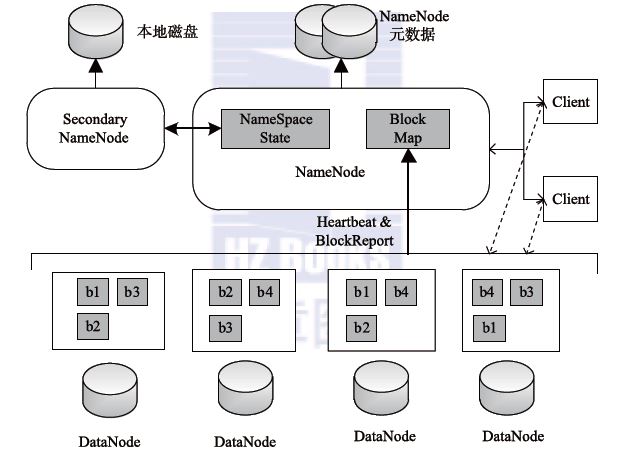
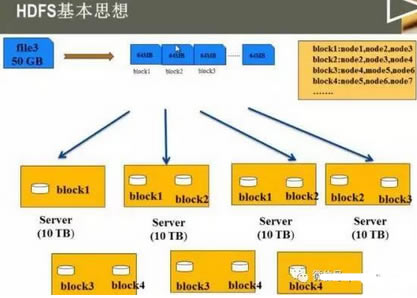
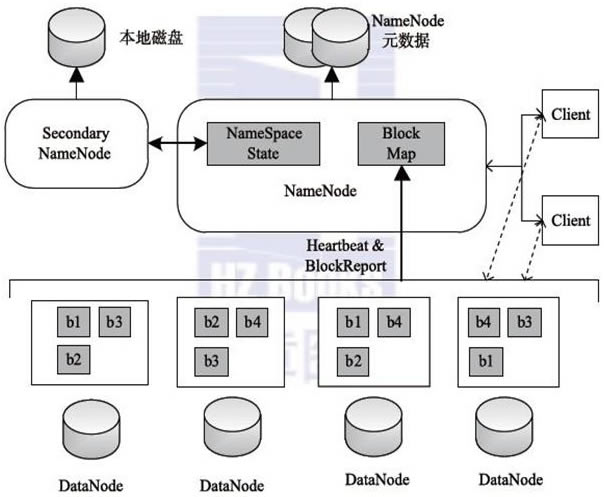
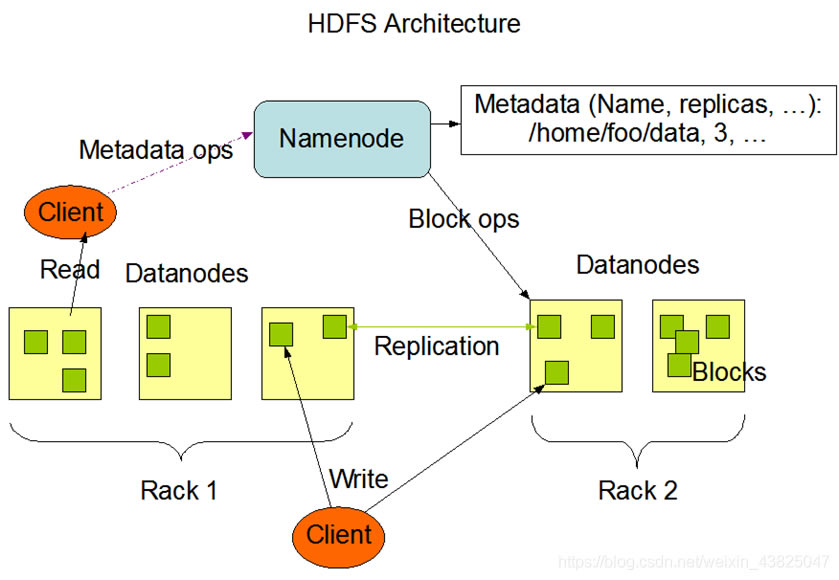
��1. HDFS��Hadoop�ֲ�ʽ�ļ�ϵ�y(t��ng)�ĽM��: Hadoop�ֲ�ʽ�ļ�ϵ�y(t��ng)�����惦(ch��)�dz���Ĕ�(sh��)��(j��)�ļ�����������(g��)Hadoop���B(t��i)ϵ�y(t��ng)�ṩ�����Ĵ惦(ch��)����(w��). ���ȣ����g(sh��)��(x��)��(ji��) 1. ���ڹ����Ĺ�(ji��)�c(di��n)�Q��NameNode 2. ���ڴ惦(ch��)�Ĺ�(ji��)�c(di��n)�Q��DataNode 3. Ԫ��(sh��)��(j��): ���ڴ惦(ch��)NameNode�Բ���DataNode��Ϣ �惦(ch��)����Ϣ: a. �c�ļ�����(du��)��(y��ng)���ļ��K b. ÿ��(g��)�ļ��K��(du��)��(y��ng)�Ĺ�(ji��)�c(di��n)λ�� c. ÿ��(g��)�ļ��K����(du��)��(y��ng)�����(f��)��λ��
d. ����: /test/a.log,3��{b1��b2}��[{b1: [h0��h1��h3]}��{b2: [h0��h2��h4]}]]����ʾ�惦(ch��)���ļ��Ǵ惦(ch��)��/ testĿ��е�.log��Ĭ�J(r��n)������(sh��)��3������2�K 4. ���惦(ch��)�Ĕ�(sh��)��(j��)�гɉKhdfs����Щ����ģ�K��ÿ��(g��)�K�Q��һ��(g��)�K��Ȼ��ÿ��(g��)�K�惦(ch��)��ij��(g��)DataNode�� 5. ÿ��(g��)�K��Ĭ�J(r��n)��С��128M��hadoop2.0���� hadoop1.0��Ĭ�J(r��n)��С��64M. 6.HDFS������ļ��K������ԓ��ݷQ�鸱��-��(f��)�� 7. HDFS�еĸ�����(sh��)Ĭ�J(r��n)�������ļ��K��HDFS�о�����������. �ς��ļ���HDFS���Ԅ�(d��ng)���ԓ�ļ����֞�ɷݣ���������. 8. ���DataNode���F(xi��n)���ϣ�NameNode��(hu��)�Ԅ�(d��ng)��(f��)�ƴ�DataNode�д惦(ch��)�ĸ��������������������(ji��)�c(di��n)�ϣ��Դ_������(g��)��Ⱥ�еĸ�����(sh��)�� 9. NameNode�е�Ԫ��(sh��)��(j��)�������ڃ�(n��i)���У��Ա�����xȡ�͌�(xi��)��. ÿ��(g��)Ԫ��(sh��)��(j��)�Ĵ�С�s��150��(g��)�ֹ�(ji��). 10. HDFS���m�ϴ惦(ch��)������С�ļ�����?y��n)������С�ļ������ɴ�����Ԫ�?sh��)��(j��)���@����(d��o)��NameNode�Ĵ���?j��)?n��i)�汻ռ�ã��Ķ��p���x��(xi��)NameNode��Ч��.
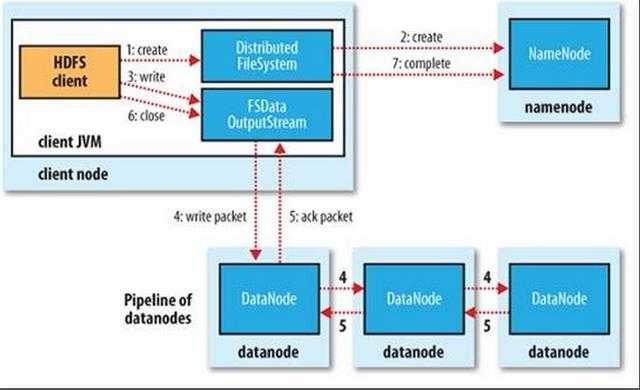
11. ����(d��ng)HDFS: start-dfs.sh ���҂�ʹ�ÈDƬ��(l��i)�M��ÿ��(g��)ģ�K֮�g���P(gu��n)ϵ���ں��m(x��)�����Ќ��M(j��n)�о��w������
�������(g��)HDFS��ҕ��惦(ch��)��(sh��)��(j��)�Ă}(c��ng)��(k��)���tNamenode��Ч��ԓ�}(c��ng)��(k��)�Ĺ���T. �M(j��n)�룬�˳����ı��ͨ�^(gu��)Namenode; Ԫ��(sh��)��(j��)��Ч�ڷ��(l��i)��. ��(d��ng)�Ñ��(zh��)�в�ԃ���ĵȲ����r(sh��)�������ҵ�Namenode�Ĺ���T������T���ƽ�Ԫ��(sh��)��(j��)�ķ��(l��i)��. ���(l��i)��ӛ��ļ�����Щ���ֱ��ֳɎײ��֣��@Щ���ַ����Ă�(g��)�������Լ�ԓ��Ϣ�����λ��. Datanode���Դ���ҕ��ԓ�}(c��ng)��(k��)���ض��惦(ch��)��Ϣ�ļ��� �ڶ�����ֹ 1. ����������һ��(g��)��(sh��)��(j��)�K 2. �K��HDFS�Д�(sh��)��(j��)�惦(ch��)�Ļ�����λ
3. Ĭ�J(r��n)ÿ��(g��)�^(q��)�K��128M 4. �и�Ŀ��: a. �܉�惦(ch��)�����ļ����������ļ��ָ���䵽��ͬ��DataNode�ϣ��Ԝp�p����(w��)���ĉ����� b. �����܉��M(j��n)�п��ق�ݣ��ָ��ÿ��(g��)С�K����ͬ�r(sh��)�惦(ch��). ����һ��؛��һ�ӣ����x3��(g��)С܇(ch��)��Ч�ʌ��ȃHʹ��1��(g��)С܇(ch��)��Ч�ʸߣ�ُ(g��u)��܇(ch��)�� ����NameNode 1. NameNodeؓ(f��)؟(z��)����DataNode�;S�o(h��)Ԫ��(sh��)��(j��). ��2. ��Hadoop 1.0�У�ֻ��һ��(g��)NameNode�����Ҵ��چ��c(di��n)��(w��n)�}�����һ��(g��)NameNode���F(xi��n)���ϣ��t����(g��)HDFS����(hu��)�c���� ��2.0�У�����ȫ�ֲ�ʽ�У��������O(sh��)��2��(g��)NameNode�����^(gu��)2��(g��)NameNode��(hu��)��(d��o)���x�e��������(w��n)�}hdfs����Щ����ģ�K���@������HDFS��Ч��. �ɂ�(g��)���ڹ�����һ��(g��)̎�ڂ��à�B(t��i)�������ˆ��c(di��n)��(w��n)�}�� ��3. Ԫ��(sh��)��(j��)�惦(ch��)�ڃ�(n��i)��ʹűP(p��n)��
�� ��4. ��Ԫ��(sh��)��(j��)�惦(ch��)�ڃ�(n��i)���е�Ŀ���Ǟ��˿����x��(xi��). ��5. Ԫ��(sh��)��(j��)�惦(ch��)�ڴűP(p��n)�����M(j��n)�б����֏�(f��) ��6. Ԫ��(sh��)��(j��)�Ĵ惦(ch��)λ����hadoop.tmp.dir���Դ_��. ���δ���ã��tĬ�J(r��n)ֵ��/ tmp����˱�����ôˌ��ԣ���?y��n)�tmpĿ���һ��(g��)�R�r(sh��)Ŀ䛣�����Linux�Л](m��i)�����ă�(n��i)�棬���Ԅh���r(sh��)��Ո(q��ng)���ȿ��]tmpĿ��е��ļ��� ��7. Ԫ��(sh��)��(j��)�惦(ch��)��dfs / name /��(d��ng)ǰĿ��� ��8. ӛ�Ԫ��(sh��)��(j��)���ļ�: ��a. ��: ����ӛ䛲������ļ� ��b. fsimage: ӛ�Ԫ��(sh��)��(j��)���ļ�. ���ļ��е�Ԫ��(sh��)��(j��)���nj�(sh��)�r(sh��)��. ��10. ��(n��i)���е�Ԫ��(sh��)��(j��)�nj�(sh��)�r(sh��)�� ��11. ��(d��ng)ÿ��(g��)��(xi��)�����L��(w��n)NameNode�r(sh��). �˲�������ӛ���eidts�ļ���. ������ļ��ѳɹ���(xi��)�루�ڴűP(p��n)�У����t���������µ���(n��i)��. ��(n��i)����³ɹ��ɹ���Ϣ���l(f��)�ͻؿ͑��ˣ��Ȍ�(xi��)��űP(p��n)��Ȼ���ٌ�(xi��)���(n��i)���Դ_����(sh��)��(j��)һ���ԣ� 12. fsimage�е�Ԫ��(sh��)��(j��)+��(n��i)����edits = metadata�еIJ��������еIJ�������fsimage. �˕r(sh��)��fsimage�еĔ�(sh��)��(j��)�c��(n��i)���еĔ�(sh��)��(j��)һ��. ��13. ���NameNode������(d��ng)���tԪ��(sh��)��(j��)���ĴűP(p��n)�л֏�(f��) ��14. HDFS������(d��ng)�r(sh��)��HDFS���Ԅ�(d��ng)������������fsimage�ļ����Դ_����(n��i)���������µ�Ԫ��(sh��)��(j��).
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո(q��ng)�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀(g��)�ˌW(xu��)��(x��)�y(c��)ԇʹ�ã�Ո(q��ng)?ji��n)����d��24С�r(sh��)��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ(f��)��Ո(q��ng)֧��ُ(g��u)�I(m��i)ܛ����ܛ����
��վ�����YԴȫ����(l��i)���ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո(q��ng)���r(sh��)֪ͨ�҂�(),�҂���(hu��)���r(sh��)̎��.
Copyright © 2018-2020 �}��ϵ�y(t��ng) �֙C(j��)վ �P(gu��n)�ڱ�վ