|
�S���Ƽ��İlչ���֙C���҂��������а����˺���Ҫ�Ľ�ɫ���֙C�ڱ����҂������ͬ�r��Ҳ�����҂���ɺ���Ҫ��Ӱ�.�֙C�ѽ��ɞ����҂��ı���Ʒ�����H��ͨӍ���ߣ����Һܴ�̶��϶��NJʘ����ܡ��֙C������Ҫָ���b�������֙C�ϵ�ܛ��������ԭʼϵ�y�IJ����c���Ի���ʹ�֙C�����书�ܣ����Ñ��ṩ���S����ʹ���w����Ҫ�ֶΡ� ART ����ȡ��Dalvik̓�M�C�� ��� ��Dalvik�£� ����ÿ���\�еĕr�� �ֹ��a����Ҫͨ�^���r���g���D�Q��C���a�� �@���������õ��\��Ч�ʣ� ����ART �h���У� �����ڵ�һ�ΰ��b�ĕr�� �ֹ��a�͕��A�Ⱦ��g�əC���a�� ʹ��ɞ������ı��ؑ��á� ���������µ�Google I/O����ϣ� Google �l�����P��Android�����µ��\�Еr�����r�� �@����Android RunTime (ART). ART ����ȡ��Dalvik̓�M�C�� �ɞ�Androidƽ�_��Java���a�Ĉ��й��ߡ� �mȻ�ԏ�Android KitKat�� ������һЩ�P��ART����Ϣ�� ���ǻ�������һЩ�����|�ģ� ȱ�����w���g��������Ľ�B�� ���ćLԇ�C��Ŀǰ���еĸ��N��Ϣ�� �Լ����·ų��� Android L �A�[�汾��ROM����r�� ��ART�\�Еr������Ԕ���ķ�����  ������IOS�� Windows�� Tizen֮��Ƅ�ƽ�_ֱ�ӌ�ܛ�����g���܉�ֱ���\�����ض�Ӳ��ƽ�_�ϵı��ش��a��ͬ�� Androidƽ�_�ϵ�ܛ���������g�����Ⱦ��g��ͨ�õ�“byte-code”�� Ȼ�����ھ��w���Ƅ��O���ϱ��D�Q�ɱ���ָ����С� ������Android�Q�������ʮ����r�g� Dalvik���_ʼ�r�dz����ε�Java Byte-Code����̓�M�C�� ��u���Ӹ��N�µ����ԣ� �M�㑪�ó������ܵ����� �Լ��cӲ���O��fͬ���M�� �@���а�����Android 2.2�汾������ļ��r���g��(JIT-Compiler), �Լ��S��Ķྀ��֧�֣� �Լ�����һЩ������  �������^�� �ڽ������ Android�������Bϵ�y���M����Android̓�M�C������ Ŀǰ��Dalvik̓�M�C���_�l�ѽ��o���M���ˡ� Dalvik ����OӋ�r�� ̎���������ܺ����� �Ƅ��O��ăȴ���g�dz����ޣ� ���Ҷ���32λ��ϵ�y�� ����Google�_ʼ����һ���µ�̓�M�C�����õ��挦δ���İlչڅ�ݡ� �@�N̓�M�C�������܉���Ŀǰ�Ķ��̎������ ����δ����8��̎�����p�ɔUչ�� �܉�M�㌦�������惦��֧�֣� �Լ��������ȴ��֧�֡� ���Ǻ��� ART���F�ˡ� ����1 �ܘ���B 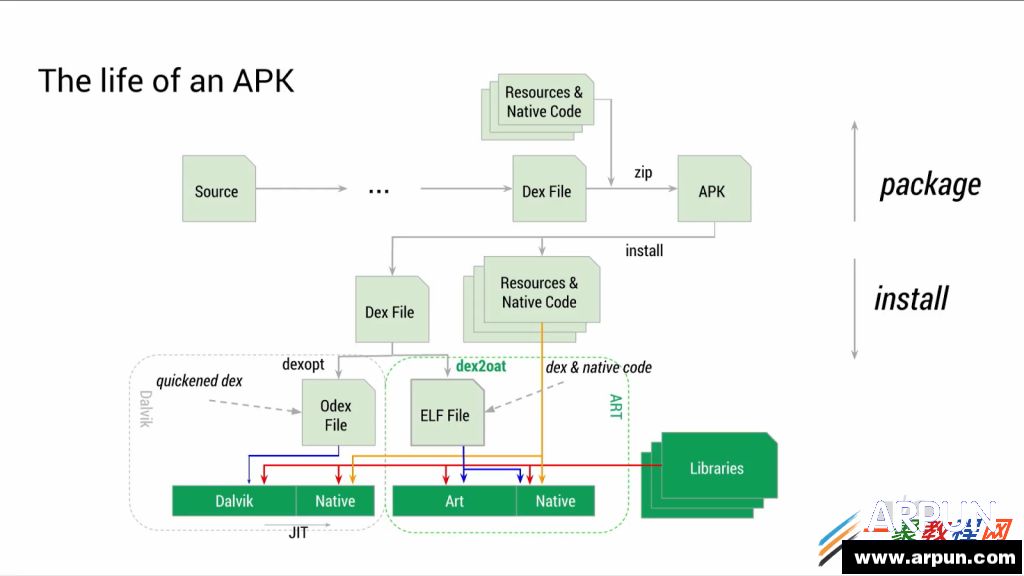 �������ȣ� ART����Ҫ�OӋ���������ȫ��������Dalvik���\�е�byte-code�� ��dex(Dalvik executable)�� �@�ӵ�Ԓ�� ���ڳ���T���f�� �Ͳ���Ҫ�����¾��g���еij��� ֱ����APK�Ϳ�����Dalvik��ART̓�M�C���\�С� ART����������׃���� ����ʹ���A���g���g(Ahead-of-Time compile)ȡ��Dalvik�еļ��r���g���g(Just-In-Time compile)�� ֮ǰ�� �ڑ��ó���ÿ�Έ��еĕr�� ̓�M�C��Ҫ��bytecode���g�ɱ��شa���У� ����ART���@�N���g����ֻ�����һ�Σ� �S��ԓ���ó���Ĉ��ж�����ͨ�^ֱ�ӈ��б������ı��شa��ɡ� ��Ȼ�� �@�N�A���g���g�� ��Ҫռ���~��Ĵ惦���g���惦���شa�� �������F���Ƅ��O��Ĵ惦���gԽ��Խ�� �@�N���g�ŵ��ԑ��á� �����@�N�A���g���gʹ�úܶ�ԭ��o�����еľ��g�������g���µ�Androidƽ�_�ϳɞ���ܡ� �����aֻ�����g�̓���һ�Σ� ���ֵ�û��M����ĕr�g���@�ξ��g�ϣ� �Ա��M�и���ă����� Google��ʾ�� �F�ڿ����ڑ��ó�������w���a���g���M�и��ߌӴεă����� ��龎�g���F���܉����ó�������w���a�� ��֮ǰ�ļ��r���g�� ���g��ֻ�ܿ������������ó�����ij���������߷dz�С��һ���ִ��a�� ����ART�� ���a�Ю����z�鎧�����_�N�^�ֿ��Ա��⣬ �������ͽӿڵ��{��Ҳ�ӿ��˺ܶࡣ ����@���ֹ��ܵ��������ӵ�“dex2oat”�M���� �Á����Dalvik�Ќ�����“dexopt”�M���� Dalvik�е� Odex�ļ�(�������dex)�ļ��� ��ART��Ҳ��ELF�ļ������ˡ� �������ARTĿǰ���g����ELF�Ɉ����ļ��� �Ⱥ˾Ϳ���ֱ�ӌ��d��ȴ��еĴ��a�M�з�퓹����� �@Ҳ���������Ӹ�Ч�ăȴ������ �Լ����ٵăȴ�ռ�á� �f���@� �ҷdz�����Ⱥ��е�KSM(Kernel same-page merging)��ART�Е���ʲô�ӵ�Ӱ푣� ��ԓ�������e��Ч���ɡ� �҂���Ŀ�Դ��� ����ART���m���r�g��Ӱ�Ҳ�Ƿdz��@���ġ� ��鲻����Ҫ��ገ��У� JITҲ�����ڳ����\�Еr������ �@�ӕ�ֱ�ӹ�ʡCPU��Ҫ���е�ָ��� �����늽��͡� ��������A���g�r�����˸�������̓����� ���g�ĕr�g��׃�L�� �@��ART���ܕ�������һ�������á� ������Dalvik̓�M�C�� ���O���״Ά��Ӽ����ó����һ�ΰ��b�r�� ��Ҫ���M�ĕr�g���á� Google�Q�� �@�N�r�g�ϵ����Ӳ�����ô�ֲ��� ����ϣ�����A���պ�ART��������������ĕr�g����Ŀǰ�� Dalvik��࣬ ��������Щ�� 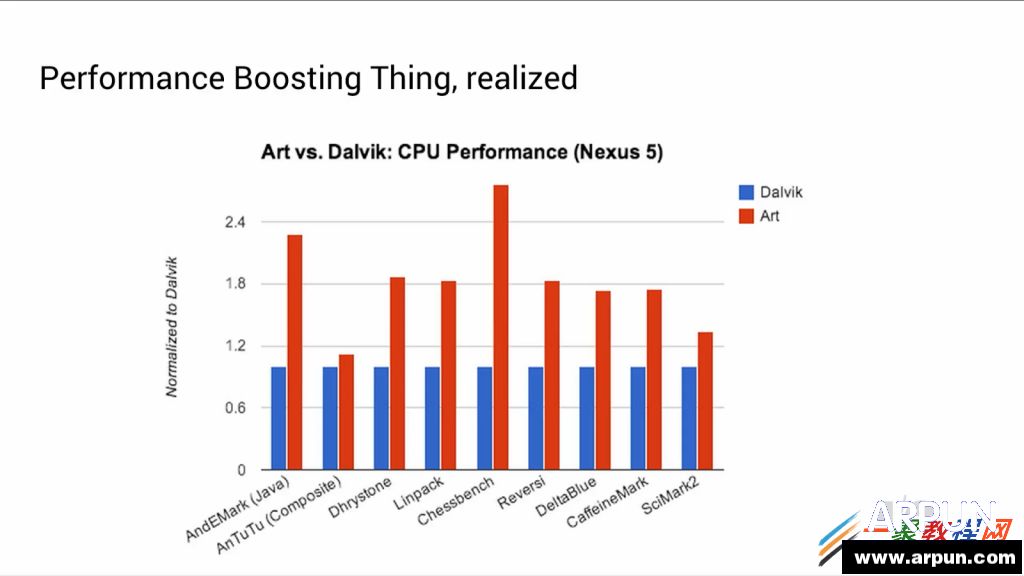 ��������ĈD�@ʾ�� ART���������������Ƿdz����@�ġ� ����ͬ�ӵĴ��a�� ���������s2�����ҡ� Google�Q�� ��Android L��K�l���ĕr�� �����AӋ����������������Chessbenchһ�ӣ� ��3x�ļ��١� ����2 �����ռ�����Փ�͌��` ����Android̓�M�C��ه�Ԅӻ��ăȴ����C�ƣ� ���Ԅ������ռ��� �@һJava�Z�Ծ���ģʽ�Ļ�ʯҲ��Androidϵ�y���Q��֮���� �dz���Ҫ��һ���֡� �@����̫�˽������ռ���������ѽ��һ�£� ���^�Ԅ������ռ��� �����f����T�ھ����^���У� ����Ҫ�Լ�ؓ؟����ȴ�Ĵ惦�ķ����ጷš� ֻ��Ҫʹ�ù̶���ģʽ��������Ҫ��׃�����ߌ��� Ȼ��ֱ������ԓ׃�����ɡ� ������\�Эh�����Ԅ��ڃȴ��з��������ăȴ���g�惦ԓ׃�����ߌ��� ����ԓ׃�����ߌ���ʧЧ�� �Ԅ�ጷ�������ăȴ档 �@�Ǻ�������Ҫ�˹��M�д惦�������^�͌Ӵ��Z�����ą^�e�� �Ԅ������ռ��ĺ�̎�ǣ� ����T�������ھ��̕r���ăȴ�����Ć��}�� ��Ȼ�� �@Ҳ���д��r�ģ� �Ǿ��dz���T�o�����ƃȴ�Εr�����ጷţ� ����o������Ҫ�r�M�Ѓ���(Java�Z����һЩ���̽ӿڿ��Թ�����T�ֹ��������� �����Ʒ�ʽ����������). ����Android������Dalvik�������ռ��C�����v�˺ܾá� Androidƽ�_�ăȴ��ձ��^С�� ÿ�Α��ó�����Ҫ����ȴ棬 ���ѿ��g(����o���ó����һ�K�ȴ���g)�����ṩ��˴�С�Ŀ��g�r�� Dalvik�������ռ����͕����ӡ� �����ռ�������v�����ѿ��g�� �鿴ÿһ�����ó������Č��� �������пɵ��_�Č���(��߀����ʹ�õČ���)��ӛ�� ������Щ�]�И�ӛ�Č�����gጷŵ��� ������Dalvik̓�M�C�У� �����ռ������е��^�̌����ɴΑ��ó����ͣ�D�� ����һ���ڱ�v�ѵ�ַ���g�A�Σ� ������һ���ǘ�ӛ�A�Ρ� �������^ͣ�D�� �����ó����������ڈ��е��M�̌���ͣ�� ���ͣ�D�r�g�^�L�� ���������ó�������Ⱦ�r���F�G���F�� �M�������ó���Ŀ��D�F�� ����Ñ��w ����Google�Q�� ��Nexus 5�֙C�ϣ� �@�Nͣ�D��ƽ���L����54ms�� �@��ͣ�D�r�g������ƽ��ÿ�������ռ��������ڑ��ó�����Ⱦ�@ʽ�r�G��4���ġ� �������Լ��Ľ��͜yԇ������ �������ó���IJ�ͬ�� ͣ�D�ĕr�g���ܕ�����ܶࡣ ���磬 �ڹٷ���FIFA���ó����@һ���ͳ����У� �����ռ���ͣ�D���dz������� ����07-01 15:56:14.275: D/dalvikvm(30615): GCFORALLOC freed 4442K, 25% free 20183K/26856K, paused 24ms, total 24ms ����07-01 15:56:16.785: I/dalvikvm-heap(30615): Grow heap (frag case) to 38.179MB for 8294416-byte allocation ����07-01 15:56:17.225: I/dalvikvm-heap(30615): Grow heap (frag case) to 48.279MB for 7361296-byte allocation ����07-01 15:56:17.625: I/Choreographer(30615): Skipped 35 frames! The application may be doing too much work on its main thread. ����07-01 15:56:19.035: D/dalvikvm(30615): GCCONCURRENT freed 35838K, 43% free 51351K/89052K, paused 3ms+5ms, total 106ms ����07-01 15:56:19.035: D/dalvikvm(30615): WAITFORCONCURRENTGC blocked 96ms ����07-01 15:56:19.815: D/dalvikvm(30615): GCCONCURRENT freed 7078K, 42% free 52464K/89052K, paused 14ms+4ms, total 96ms ����07-01 15:56:19.815: D/dalvikvm(30615): WAITFORCONCURRENTGC blocked 74ms ����07-01 15:56:20.035: I/Choreographer(30615): Skipped 141 frames! The application may be doing too much work on its main thread. ����07-01 15:56:20.275: D/dalvikvm(30615): GCFORALLOC freed 4774K, 45% free 49801K/89052K, paused 168ms, total 168ms ����07-01 15:56:20.295: I/dalvikvm-heap(30615): Grow heap (frag case) to 56.900MB for 4665616-byte allocation ����07-01 15:56:21.315: D/dalvikvm(30615): GCFORALLOC freed 1359K, 42% free 55045K/93612K, paused 95ms, total 95ms ����07-01 15:56:21.965: D/dalvikvm(30615): GCCONCURRENT freed 6376K, 40% free 56861K/93612K, paused 16ms+8ms, total 126ms ����07-01 15:56:21.965: D/dalvikvm(30615): WAITFORCONCURRENTGC blocked 111ms ����07-01 15:56:21.965: D/dalvikvm(30615): WAITFORCONCURRENTGC blocked 97ms ����07-01 15:56:22.085: I/Choreographer(30615): Skipped 38 frames! The application may be doing too much work on its main thread. ����07-01 15:56:22.195: D/dalvikvm(30615): GCFORALLOC freed 1539K, 40% free 56833K/93612K, paused 87ms, total 87ms ����07-01 15:56:22.195: I/dalvikvm-heap(30615): Grow heap (frag case) to 60.588MB for 1331732-byte allocation ����07-01 15:56:22.475: D/dalvikvm(30615): GCFORALLOC freed 308K, 39% free 59497K/96216K, paused 84ms, total 84ms ����07-01 15:56:22.815: D/dalvikvm(30615): GCFORALLOC freed 287K, 38% free 60878K/97516K, paused 95ms, total 95ms ���������log�Ǐ�FIFA���ó����\�к�Ď���犕r�g���ȡ�ġ� �����ռ����ڶ̶̵�8��ȱ�������9�Σ� �����ó������D��603ms�� �G���_214�Ρ� �^������Ŀ��D�����ԃȴ����Ո�� ��log����”GC_FOR_ALLOC“�˺������� ����ART�����������ռ�ϵ�y���������OӋ�͌��F�� ��������Щ���ȣ� ����o��ʹ��ART�\����ͬ�đ��ó��� ����ͬ�Ĉ�������ȡ��log�� ����07-01 16:00:44.531: I/art(198): Explicit concurrent mark sweep GC freed 700(30KB) AllocSpace objects, 0(0B) LOS objects, 792% free, 18MB/21MB, paused 186us total 12.763ms ����07-01 16:00:44.545: I/art(198): Explicit concurrent mark sweep GC freed 7(240B) AllocSpace objects, 0(0B) LOS objects, 792% free, 18MB/21MB, paused 198us total 9.465ms ����07-01 16:00:44.554: I/art(198): Explicit concurrent mark sweep GC freed 5(160B) AllocSpace objects, 0(0B) LOS objects, 792% free, 18MB/21MB, paused 224us total 9.045ms ����07-01 16:00:44.690: I/art(801): Explicit concurrent mark sweep GC freed 65595(3MB) AllocSpace objects, 9(4MB) LOS objects, 810% free, 38MB/58MB, paused 1.195ms total 87.219ms ����07-01 16:00:46.517: I/art(29197): Background partial concurrent mark sweep GC freed 74626(3MB) AllocSpace objects, 39(4MB) LOS objects, 1496% free, 25MB/32MB, paused 4.422ms total 1.371747s ����07-01 16:00:48.534: I/Choreographer(29197): Skipped 30 frames! The application may be doing too much work on its main thread. ����07-01 16:00:48.566: I/art(29197): Background sticky concurrent mark sweep GC freed 70319(3MB) AllocSpace objects, 59(5MB) LOS objects, 825% free, 49MB/56MB, paused 6.139ms total 52.868ms ����07-01 16:00:49.282: I/Choreographer(29197): Skipped 33 frames! The application may be doing too much work on its main thread. ����07-01 16:00:49.652: I/art(1287): Heap transition to ProcessStateJankImperceptible took 45.636146ms saved at least 723KB ����07-01 16:00:49.660: I/art(1256): Heap transition to ProcessStateJankImperceptible took 52.650677ms saved at least 966KB ����ART��Dalvik�IJ�e�dz��� �µ��\�Еr�ȴ����H�Hͣ�D��12.364ms�� �\����4��ǰ�_�����ռ��� �Լ�2�κ��_�����ռ��� �ڑ��ó�����е��^���У� ���ó���Ķѿ��g��С���]�����ӣ� ��Dalvik̓�M�C�жѿ��g��������4�Ρ� �G���Ă������棬 ART̓�M�CҲ������63���� ���������@��ʾ���� ֻ���^��һ���_�l�������Ƶđ��ó�������ĵ�һ�������� ��鼴ʹ��ART̓�M�C�У� �@�����ó���߀�ǁG���˲��َ���Ⱦ�D�� ���^�����log������Ȼ���Ѕ����rֵ�� ����ţ�Ƶij���T�]�ׂ��� �������Android���]�k���_�l�ĺ������� Android��Ҫ��holdס�@�N��r�� ����ART��һЩͨ����Ҫ�����ռ������Ĺ����� ��ֽo���ó�������ɡ� �@�ӣ� Dalvik������v�ѿ��g����ĵ�һ��ͣ�D�� �ͱ���ȫ�����ˡ� ���ڶ���ͣ�DҲ���һ��A�������g (packard pre-cleaning)�đ��ö����s�̡� ʹ��ԓ���g�� ֻ��Ҫ��������ɺ� ���εęz�����C�r��ͣ�Dһ�¼��ɡ� Google�Q�� �����ѽ��O�����@�ͣ�D�ĕr�g�s�̵�3ms���ң� ���Dalvik̓�M�C�������ռ������f�� ��������һ�����������Ľ��ͣ� �ܲ��e�ˡ� 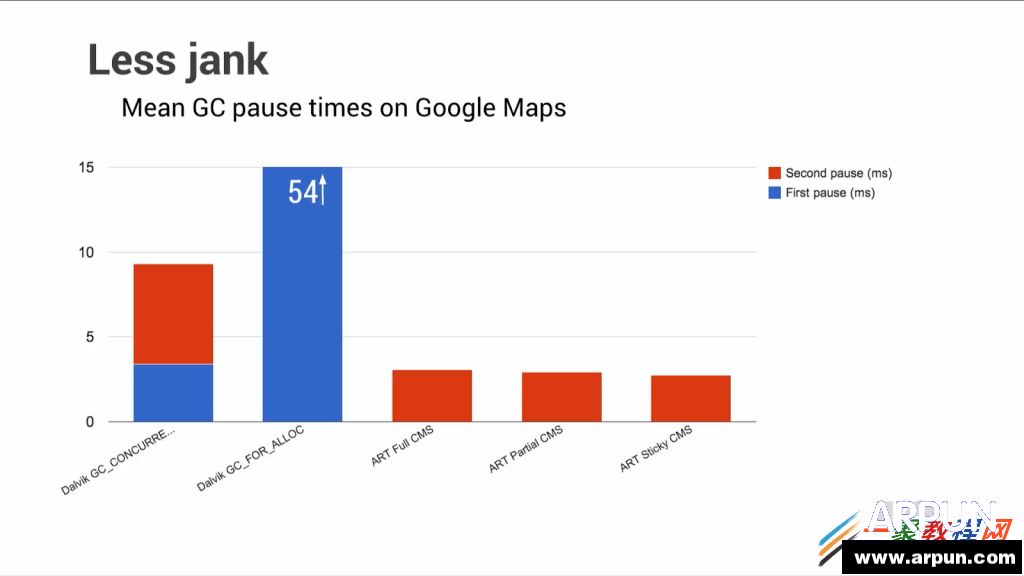 ����ART߀������һ������ij�����惦���g(large object space�� LOS)�� �@�����g�c�ѿ��g�Ƿ��_�ģ� ���^��Ȼ�v���ڑ��ó���ȴ���g�С� �@һ������OӋ�Ǟ���ART���Ը��õĹ����^��Č��� ����λ�D����(bitmaps)�� �ڌ��ѿ��g�ֶΕr�� �@�N�^��Č��������һЩ���}�� ���磬 �ڷ���һ�������r�� ���������ͨ���� �����������ռ������ӵĴΔ����Ӻܶࡣ �����@��������惦���g��֧�֣� �����ռ�����ѿ��g�ֶζ����l�{�ôΔ�������ͣ� �@�������ռ������������Ӻ����ăȴ���䣬 �Ķ������\�Еr�_�N�� ����һ���ܺõ����ӣ� �����\��Hangouts(�h��)���ó���r�� ��Dalvik̓�M�C�У� �҂��ܿ�������������ȴ棬 �\��GC�����µ�ͣ�D�� ����07-01 06:37:13.481: D/dalvikvm(7403): GCEXPLICIT freed 2315K, 46% free 18483K/34016K, paused 3ms+4ms, total 40ms ����07-01 06:37:13.901: D/dalvikvm(9871): GCCONCURRENT freed 3779K, 22% free 21193K/26856K, paused 3ms+3ms, total 36ms ����07-01 06:37:14.041: D/dalvikvm(9871): GCFORALLOC freed 368K, 21% free 21451K/26856K, paused 25ms, total 25ms ����07-01 06:37:14.041: I/dalvikvm-heap(9871): Grow heap (frag case) to 24.907MB for 147472-byte allocation ����07-01 06:37:14.071: D/dalvikvm(9871): GCFORALLOC freed 4K, 20% free 22167K/27596K, paused 25ms, total 25ms ����07-01 06:37:14.111: D/dalvikvm(9871): GCFORALLOC freed 9K, 19% free 23892K/29372K, paused 27ms, total 28ms �����҂������е������ռ�log�н�ȡ������һ�Ρ� ���е��@ʽ(GC_EXPLICIT)�Ͳ��l(GC_CONCURRENT)�������ռ����б��^ͨ�õ������;S�o���{�á� GC_FOR_ALLOC�t���ڃȴ�������Lԇ�����µăȴ���g�� ���ѿ��g�����Õr�� �{�õġ� �����log�У� �҂��ܿ����ѿ��g���ֶβ������U���˶ѿ��g�� ����Ȼ�o���b�´��� ���������������^���У� ͣ�D�r�g�L�_90ms�� �������֮�£� �����@��log�Ǐ�Android L�A�[�汾��ART�\��log����ȡ�ġ� ����07-01 06:35:19.718: I/art(10844): Heap transition to ProcessStateJankPerceptible took 17.989063ms saved at least -138KB ����07-01 06:35:24.171: I/art(1256): Heap transition to ProcessStateJankImperceptible took 42.936250ms saved at least 258KB ����07-01 06:35:24.806: I/art(801): Explicit concurrent mark sweep GC freed 85790(3MB) AllocSpace objects, 4(10MB) LOS objects, 850% free, 35MB/56MB, paused 961us total 83.110ms �����҂�Ŀǰ߀��֪��log�е�”Heap Transition”���_��ʲô��˼�� ���^���Բy��ԓ�Ƕѿ��g��С���O�C�ơ� �ڑ��ó����ѽ��\��֮�� Ψһ�Č������ռ������{�ÃH���ĵ�961us�� �҂����]�����@�ν�ȡ��log֮ǰ�� �l�F�κΌ������ռ������{�ò����� �@��log�б��^��Ȥ�ģ� ����LOS�ĽyӋ�� �܉��� ��LOS����4���^��Č��� ��10MB�� �@�K�ȴ沢�]�з����ڶѿ��g�ȣ� ��t��ԓ�������Dalvik����ʾ�� ����ART�ăȴ����ϵ�y����Ҳ���،��ˡ� �mȻART���Dalvik�� �ڃȴ���䷽�棬 �܉���s25%������������ ���^Google�@Ȼ���˲��M�⣬ ���������һ���µăȴ��������ȡ����ǰʹ�õ�“malloc”�������� �����@���µăȴ�������� “rosalloc”(Runs-of-Slots-Allocator)�������ྀ��Java���ó�������c���OӋ�ġ� �˃ȴ�������и������ȵ��i�C�ƣ� ����ֱ�ӌ������Č������i�� ���nj�����������ăȴ���g���i�� �ھ��ֲ̾��^���е�С����ķ��䣬 ��ȫ���ԟoҕ�i�Ĵ����ˡ� �]�����i��Ո���ጷţ� ���ֲ̾�С������L���ٶ�Ҳ�ʹ�������ˡ� �����@���µăȴ��������������˃ȴ������ٶȣ� ���ٱ��_����10x�� ����ͬ�r�� ART�����������㷨Ҳ���˸��M�� �������Ñ�ʹ���w ���⑪�ó���Ŀ��D�� �@Щ�㷨��Google�Ȳ�Ŀǰ��Ȼ�����_�l�С� ���ڣ� Google�H�H��B��һ�����㷨�� “Moving Garbage Collector”.����˼���ǣ� �����ó����\���ں��_�r�� ������Ķѿ��g���κϲ������� ����3 64λ֧�� ����ART���OӋ�r��ֿ��]�ˌ��պ�����\�еĸ��Nƽ�_�M��ģ�K���� ��ˣ� ART�ṩ�˴����ľ��g����ˣ� ��������Ŀǰ��Ҋ���wϵ�Y���Ĵ��a�� ����ARM�� X86��MIPS�� ���а�����ARM64�� X86-64��֧�֣� �Լ���δ���F�Č�MIPS64��֧�֡�  ��������ARM��64λϵ�y�����ĺ�̎�� ��Ⱥܶ����Ѷ��˽��ˡ� ����ăȴ��ַ���g�� ���m������������ �Լ��ӽ��ܵ����������������� ����߀�Ќ�����32λ���ó���ļ��ݡ� ��������֮�⣬ Google߀��ART�����������É��s���g�� ������ART�ѿ��g�Ȳ����64λָᘵ����댧�µăȴ�ռ��׃���}�� �䌍�� �����ڈ��Еr�� ���е�ָᘶ�����32λ��ʾ�� ����64λϵ�y��ԓ���õ�64λָᘡ� 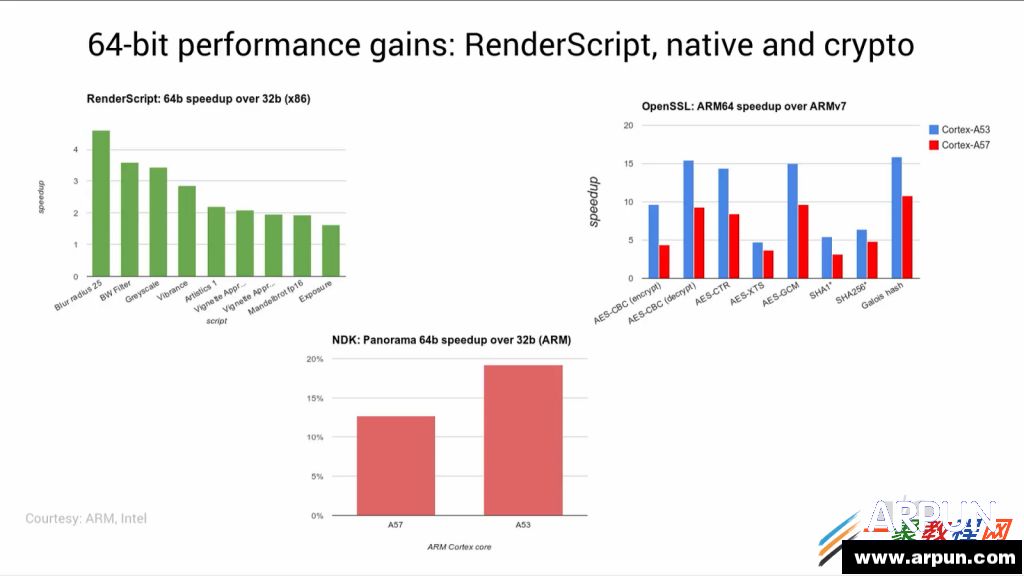 ����Google���_��һЩARM��X86ƽ�_�ϑ��ó�����64λ��32λģʽ�µ����܌��ȡ� �@ֻ��һЩ�A�[���|������ X86�����ܜyԇ��Intel�� BayTrailϵ�y���M�У� ���ڲ�ͬ��RenderScript�yԇ���� ����������2x��4.5x���ȡ� ARMƽ�_���棬 �քe��A57��A53ϵ�y�ϣ� ��crypto���������ˌ��ȡ� �@Щ������鶼��ᘌ��dz�С�����ӣ� ���Դ����Բ��� ���߀�o�����팍�H���È�������r�� �������^�� GoogleҲ�ų���һЩ��Ȥ�Ĕ����� �@Щ�������������Ȳ�ʹ�õ�ϵ�yPanorama�Ϝyԇ�ġ� ͨ�^���εď�32λABI�D�Q��64λ ABI�� �܉�@��13%��19%������������ ߀�Ђ�ϲ�˵ĽYՓ�� �Ǿ���ARM��Cortex A53��AArch64ģʽ���ܫ@������������A57��Ҫ�ࡣ ����Google߀�Q�� Ŀǰ�����̵���85%�đ��ó�����ֱ����64λģʽ���\�У� Ҳ�����f�H��15%�đ��ó�����ij�N�̶���ʹ���˱��ش��a�� ��Ҫ����64λƽ�_���gԓ���ó��� �@��Google���f����һ���dz���ă��ݡ� ���꣬ �������оƬ�S�̶��_ʼ��64λƬ��ϵ�y�ĕr�� ��32λ Androidϵ�y��64λAndroidϵ�y�ĵ��ГQ�����dz��졣 ����4 �YՓ �����Y�������B���T��棬 ART��Google�l����һ���������������� ����ARTҲ��Q�˶�����������_Androidϵ�y���T�����}�� ART ��Ч�ظ��M�˶�����ገ��Б��ó������R�Ć��}�� Ҳ�ṩ��һ���Ԅӻ��ĸ�Ч�Ĵ惦����ϵ�y�� �����_�l�߁��f�� �S���^ȥ��Ҫ�ֹ����Ӵ��a��Q�����܆��}�� �F�ڶ��ܱ�ART�p��holdס�ˡ� �����@Ҳ��ζ��Androidϵ�y�K���܉���ϵ�yƽ���ȣ� ���ó������ܷ����cIOS�ݾ������ˡ� �����M�߁��f�� �Ǽ�ϲ���ձ������顣 ����GoogleĿǰ���ڣ� ������δ��һ�Εr�g��߀���������MART�� ARTĿǰ�Ġ�r�� �c6����ǰ�ѽ�����ͬ�ˣ� �AӋ�ȵ�Android L�����l���ĕr�� �֕��з��츲�ص�׃���� ǰ;�ǹ����ģ� �҂���Ŀ�Դ��� �N�����ΰɡ� �֙CAPP�@Щ���b���֙C�����S����ʵ�ܛ�����҂���������ӷ���;��ʡ��Α��罻��ُ�ҕ�l���������W��......�҂������S�r�S�أ��S̎�M�С� |
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(),�҂������r̎��.
Copyright © 2018-2020 �}��ϵ�y���dվ �֙Cվ �P�ڱ�վ
